OPEN LINK ↗
// 2h agoRESEARCH PAPER
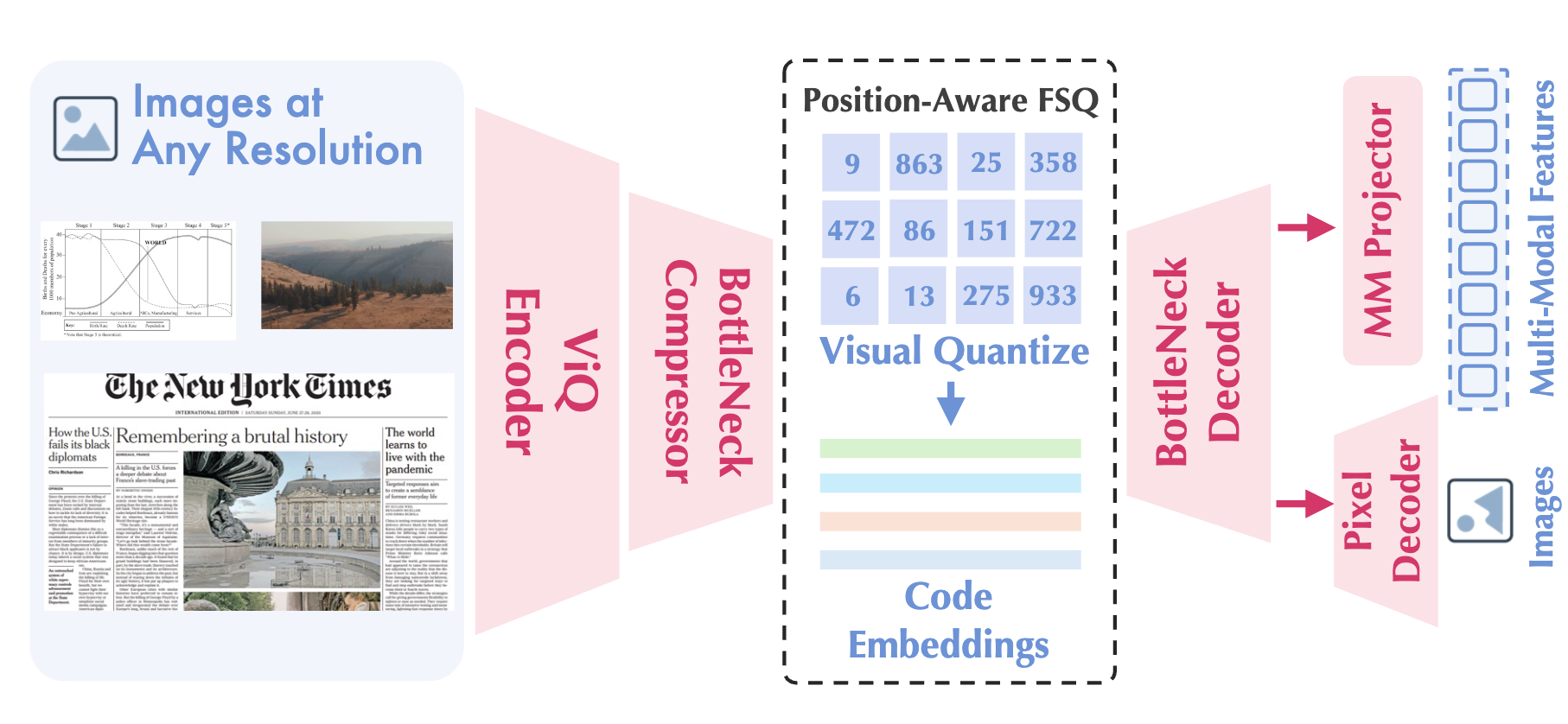
ViQ tokenizes images at any resolution
Researchers introduced ViQ, a dual-stage framework that converts visual inputs into discrete tokens while preserving both high-level semantic alignment and low-level details. By utilizing proximal representation learning and position-aware head-wise quantization, it supports native resolutions and accelerates multimodal training by 20% to 70%.
// ANALYSIS
ViQ solves a critical bottleneck in multimodal LLMs by showing that visual tokens don't have to sacrifice fine-grained detail to achieve strong text-alignment. By making discrete image tokenization resolution-agnostic, it paves the way for much cheaper and more flexible multimodal training.
- –Dual-stage optimization: Separating text-aligned pre-training from feature discretization prevents the semantic degradation typically seen in reconstruction-first quantizers like VQ-GAN.
- –Resolution flexibility: Position-aware head-wise quantization allows models to handle arbitrary aspect ratios and resolutions natively, removing the need for artificial cropping or padding.
- –Efficiency gains: Boosting training speed by 20%–70% makes it a highly attractive framework for training custom multimodal models on constrained compute budgets.
- –Open resources: The team has open-sourced both the code on GitHub and the pre-trained weights on Hugging Face, lowering the barrier to entry for developer experimentation.
// TAGS
viqllmquantizationmultimodalvisionopen-sourceresearch
DISCOVERED
2h ago
2026-06-26
PUBLISHED
2h ago
2026-06-26
RELEVANCE
7/ 10
AUTHOR
_akhaliq