OPEN LINK ↗
// 101d agoBENCHMARK RESULT
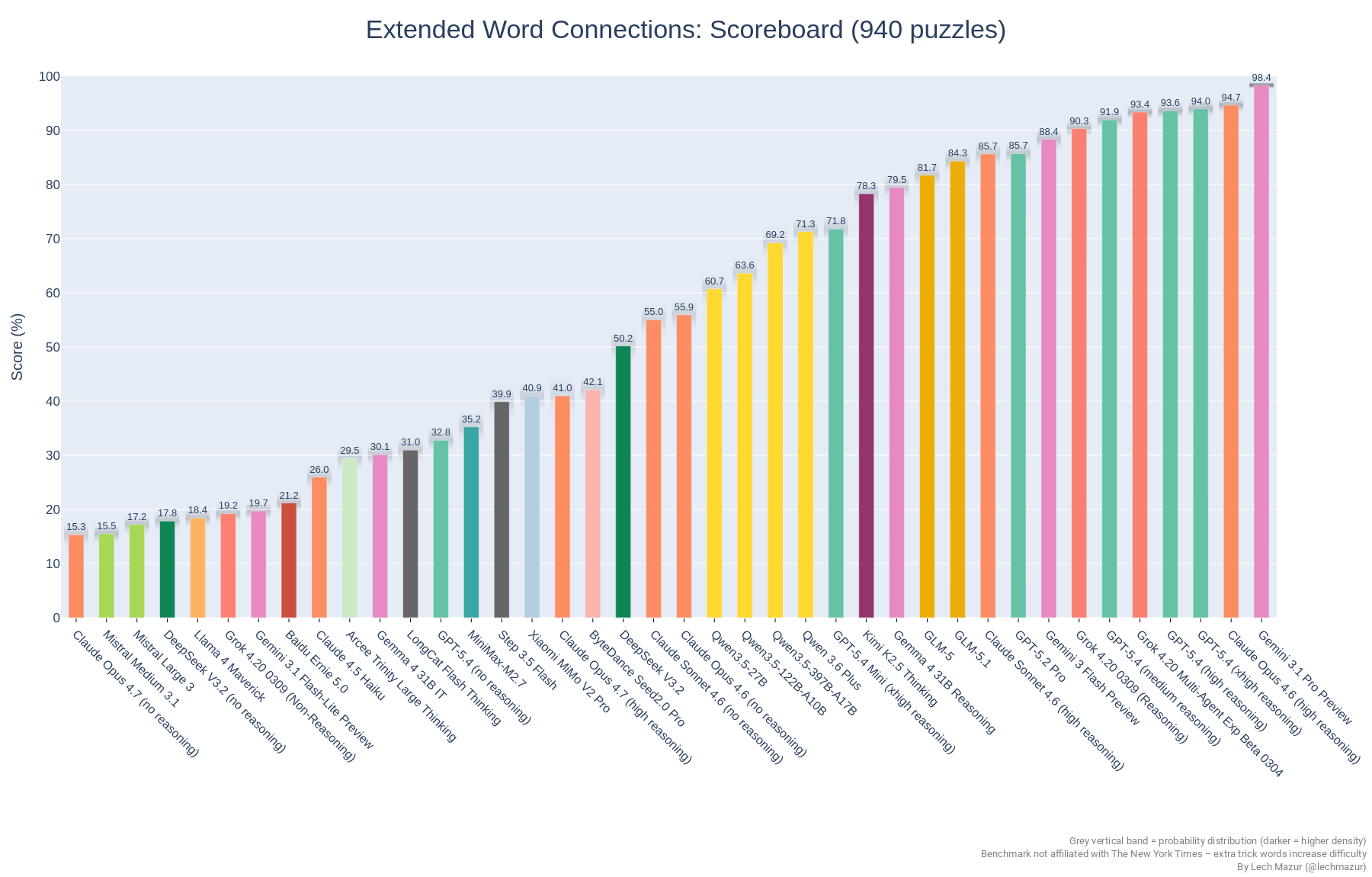
Frontier Models Pull Ahead in Extended Connections Benchmark
This Reddit post points to lechmazur’s nyt-connections benchmark repo, which evaluates LLMs on NYT Connections puzzles and now extends the test with extra trick words to reduce saturation. The current README says the benchmark has grown to 940 puzzles and tracks model scores across a broad leaderboard, with recent frontier models from Google, OpenAI, Anthropic, and xAI clustered near the top.
// ANALYSIS
Hot take: this is less a “who’s smartest” chart than a snapshot of which labs are shipping the strongest reasoning-tuned models right now.
- –The extended benchmark is the real story here: adding trick words makes the task materially harder and keeps the leaderboard meaningful.
- –Newer models dominate, which suggests recency and reasoning tuning matter more than brand mythology.
- –The top cluster is tight enough that small benchmark design choices can reshuffle rankings, so this should be read as a specialized eval, not a general IQ proxy.
- –Because the repository mixes original and extended puzzle sets, comparisons across older runs need care; the newer 940-puzzle version is not directly comparable to the older 436/759-puzzle subsets.
// TAGS
llmbenchmarknyt-connectionsreasoningevaluationopen-sourcepuzzlesai
DISCOVERED
101d ago
2026-04-17
PUBLISHED
101d ago
2026-04-17
RELEVANCE
8/ 10
AUTHOR
zero0_one1