THUDM open-sources Slime RL framework for GLM-5.2
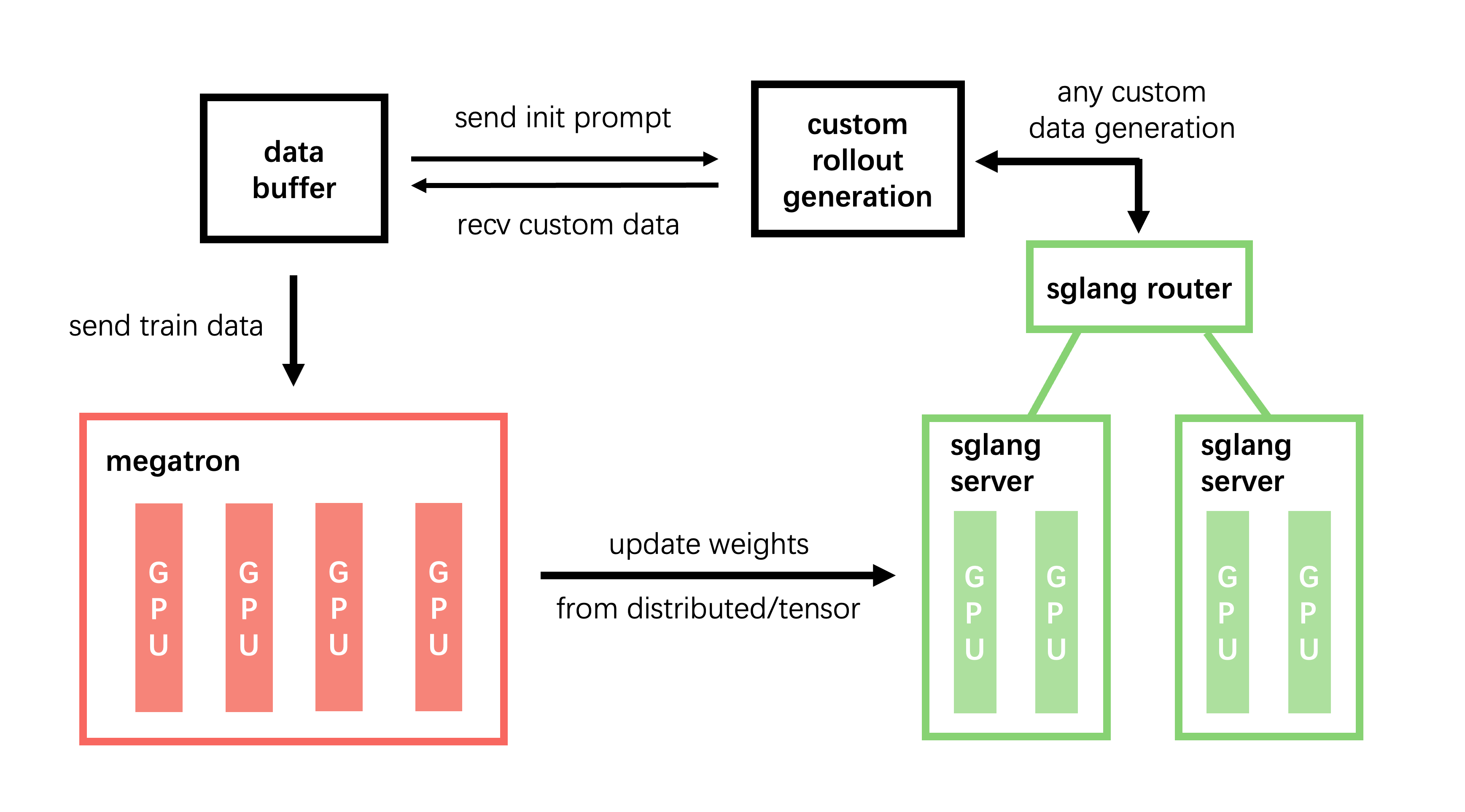
Tsinghua University's THUDM group has open-sourced Slime, the reinforcement learning (RL) post-training framework behind Zhipu AI's GLM-4 and GLM-5 series. By integrating Megatron-LM with SGLang to bridge training and inference, Slime enables parallel On-Policy Distillation (OPD) loops and completed the post-training of the 744B-parameter GLM-5.2 MoE model in approximately two days.
Making production-grade RL post-training infrastructure open source significantly lowers the barrier to entry for training large-scale agentic models.
* Unifies Megatron-LM for training and SGLang for inference rollouts, minimizing system and synchronization overhead.
* Features a TransferQueue to decouple compute processes and a Distributed Checkpoint Service for asynchronous weight syncing.
* Highly optimized for complex RL workflows like multi-turn agentic rollouts and parallel OPD loops, enabling rapid folding of expert models.
DISCOVERED
1h ago
2026-06-20
PUBLISHED
2h ago
2026-06-20
RELEVANCE
AUTHOR
jeremyphoward