OPEN LINK ↗
// 105d agoBENCHMARK RESULT
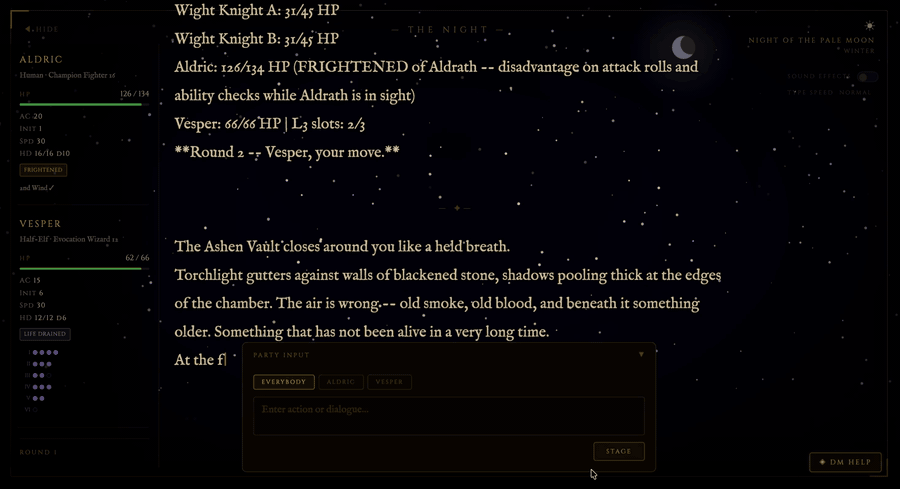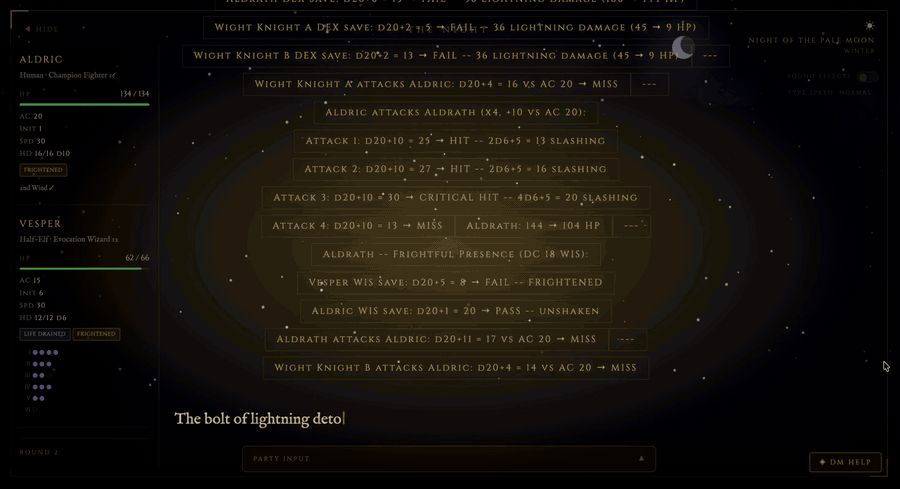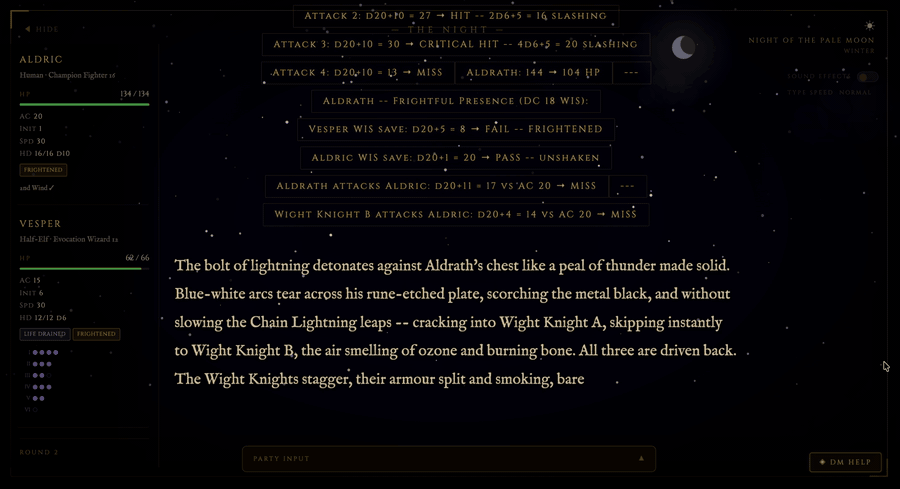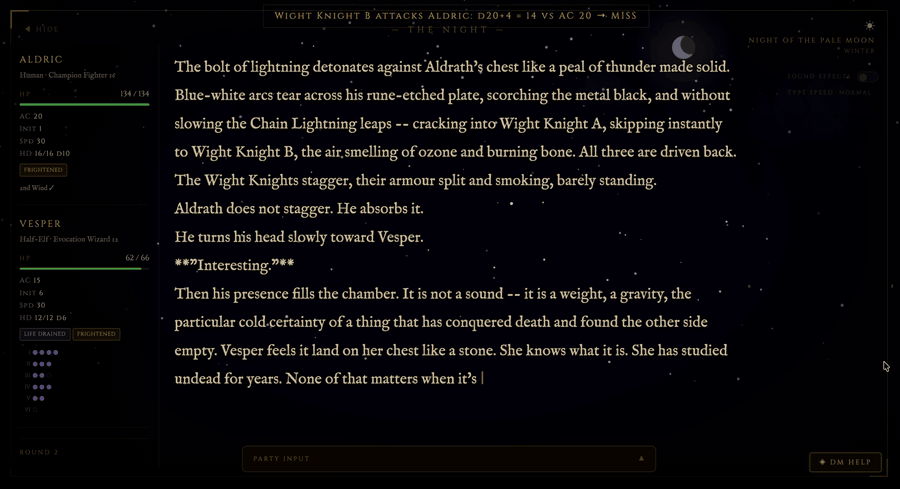
Gemma 3 27B tops tabletop GMing narrative benchmark
Bobby-Gray’s "open-tabletop-gm" project introduces an open-source "narrative probe" to evaluate the creative performance of LLMs in roleplaying scenarios. The latest results reveal that the mid-weight Gemma 3 27B model outperforms massive counterparts like Hermes 405B in atmosphere and NPC characterization, proving that parameter count isn't the primary driver of narrative "soul" in gaming applications.
// ANALYSIS
The "creative ceiling" for LLMs in gaming isn't gated by parameter count; specific tuning for atmosphere and NPC voice is more valuable than raw instruction-following discipline for tabletop applications.
- –Gemma 3 27B’s overall score of 4.33 makes it the top recommendation for local inference GMs, offering high narrative fidelity without the massive hardware requirements of frontier-class models.
- –Nemotron Nano 30B earned a category-high 4.5 in atmosphere, highlighting its specialized strength in cinematic scene-painting despite thinner dialogue capabilities.
- –Hermes 405B showed high structural discipline but "safe" writing, suggesting that massive models may suffer from over-alignment that dampens creative flair.
- –The narrative probe methodology highlights a growing need for subjective benchmarks as "tool-call compliance" becomes a solved problem for most mid-to-large models.
// TAGS
gemma-3open-tabletop-gmllmtabletop-rpgbenchmarkgaminglocal-llm
DISCOVERED
105d ago
2026-04-19
PUBLISHED
105d ago
2026-04-19
RELEVANCE
8/ 10
AUTHOR
Bobby_Gray