OPEN LINK ↗
// 2h agoINFRASTRUCTURE
DFlash achieves 15x inference speedup on Blackwell
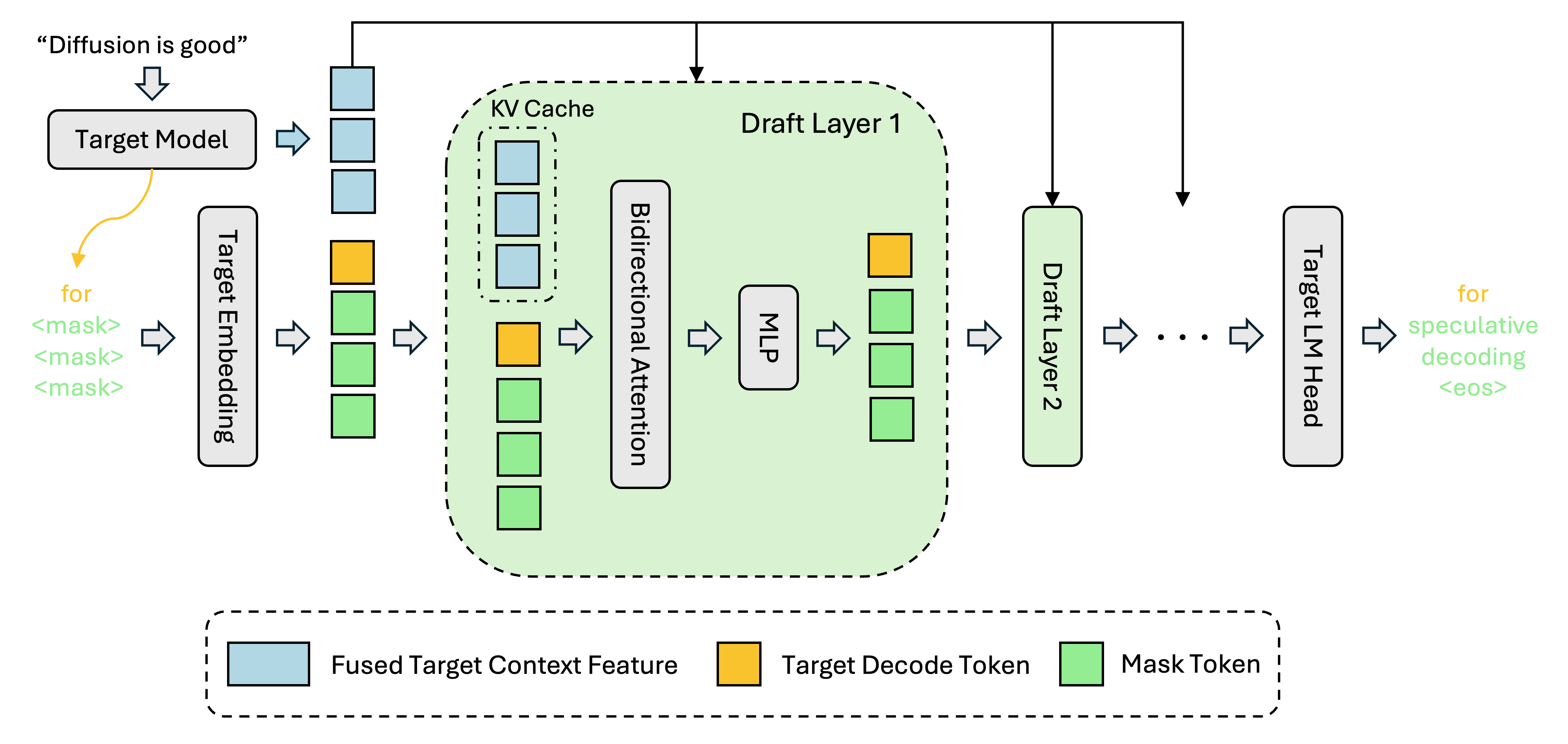
NVIDIA detailed performance benchmarks for DFlash, an open-source speculative decoding framework that uses block-diffusion drafting to generate entire token blocks in parallel. The method achieves up to 15x throughput improvements for large models on Blackwell GPUs and integrates into SGLang, vLLM, and TensorRT-LLM.
// ANALYSIS
By shifting speculative drafting from sequential generation to parallel block diffusion, DFlash shatters the throughput ceiling of traditional autoregressive decoding.
- –Parallel Drafting Breakthrough: Unlike autoregressive drafts that generate tokens sequentially, DFlash's block-diffusion drafter proposes entire token blocks in a single forward pass, fully utilizing the parallel compute of Blackwell's NVFP4 engine.
- –Lossless Acceleration: The large target model verifies the drafted block in parallel, ensuring that the model's original output quality is completely preserved while boosting speed.
- –Drop-In Ecosystem Integration: Support for vLLM, SGLang, and TensorRT-LLM combined with 20 pre-trained checkpoints on Hugging Face means developers can adopt DFlash without modifying their application code.
- –Stunning Benchmark Gains: Achieving up to 15x throughput gains for gpt-oss-120b and doubling the interactivity of Llama 3.1 8B compared to EAGLE-3 demonstrates DFlash's scalability across both massive and smaller model classes.
// TAGS
dflashnvidiainferencegpuopen-sourcellmframeworkvllm
DISCOVERED
2h ago
2026-06-25
PUBLISHED
2h ago
2026-06-25
RELEVANCE
9/ 10
AUTHOR
DIY Smart Code