LiteCode Exposes Small-Model Agent Failures
The post shares field notes from testing a CLI coding agent across small local models and free-tier cloud models, focusing on where agent workflows fail in practice. The recurring breakpoints are markdown fences, unreliable structured output, overconfident file edits, and weak read-only vs edit-action routing. The author argues that the durable fixes live in orchestration and validation, not just prompting, and says LiteCode’s design choices around token budgeting, per-file isolation, and lightweight memory improved reliability.
Hot take: small models are less useful as “smart chatbots” than they are as brittle components inside a heavily constrained agent pipeline, so most of the reliability work belongs in the wrapper, not the prompt.
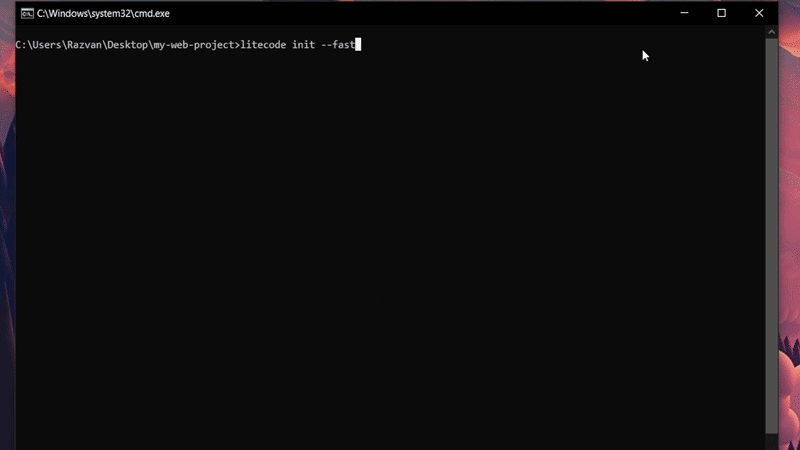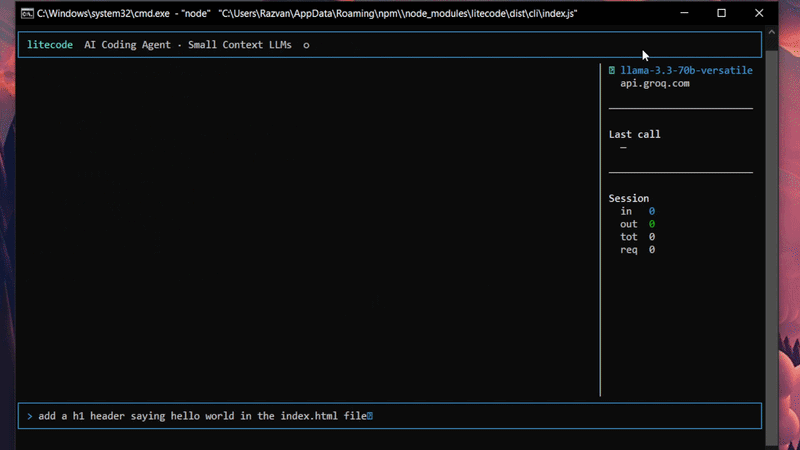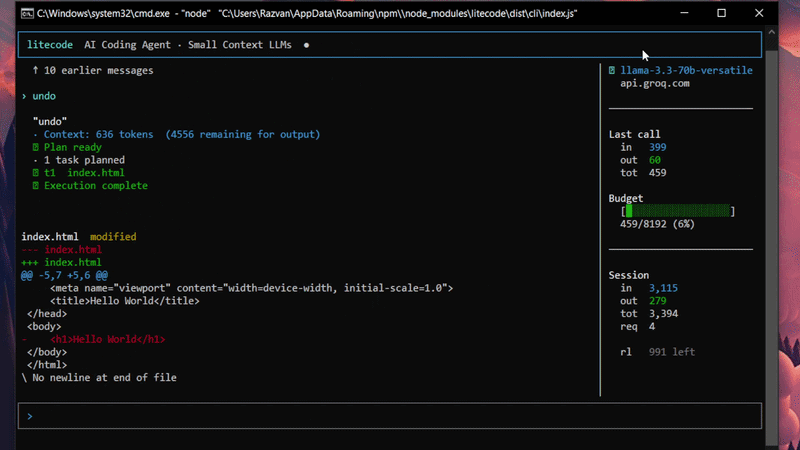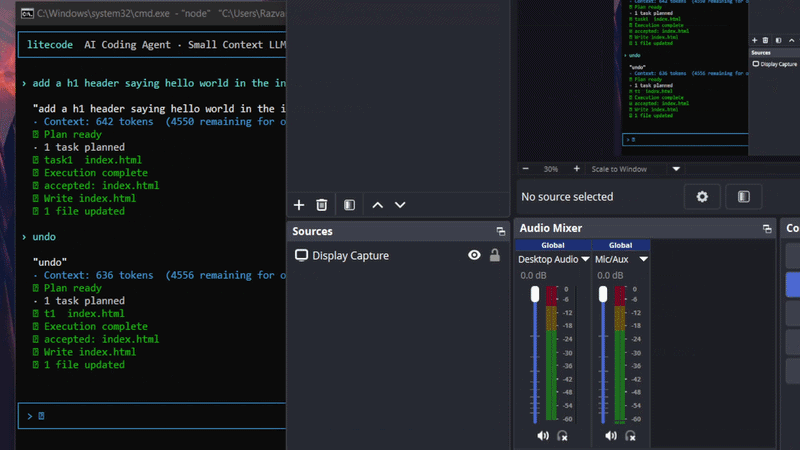
- –The strongest claim is that markdown fences and JSON validity are operational problems, not prompt-engineering problems; post-processing and validation are mandatory.
- –The write-up is most convincing where it describes orchestration failures: wrong-file edits, function-name drift, and read-only requests being misrouted into destructive actions.
- –The practical takeaways are solid: pre-call token accounting, one-file-at-a-time editing, and short state summaries are all easy wins for agent reliability.
- –The article is less a benchmark and more an implementation guide based on repeated failures, which makes it useful for builders even if the conclusions are partly anecdotal.
DISCOVERED
45d ago
2026-04-30
PUBLISHED
45d ago
2026-04-30
RELEVANCE
AUTHOR
BestSeaworthiness283