OPEN LINK ↗
// 91d agoINFRASTRUCTURE
Reddit debates local LLM hardware choices
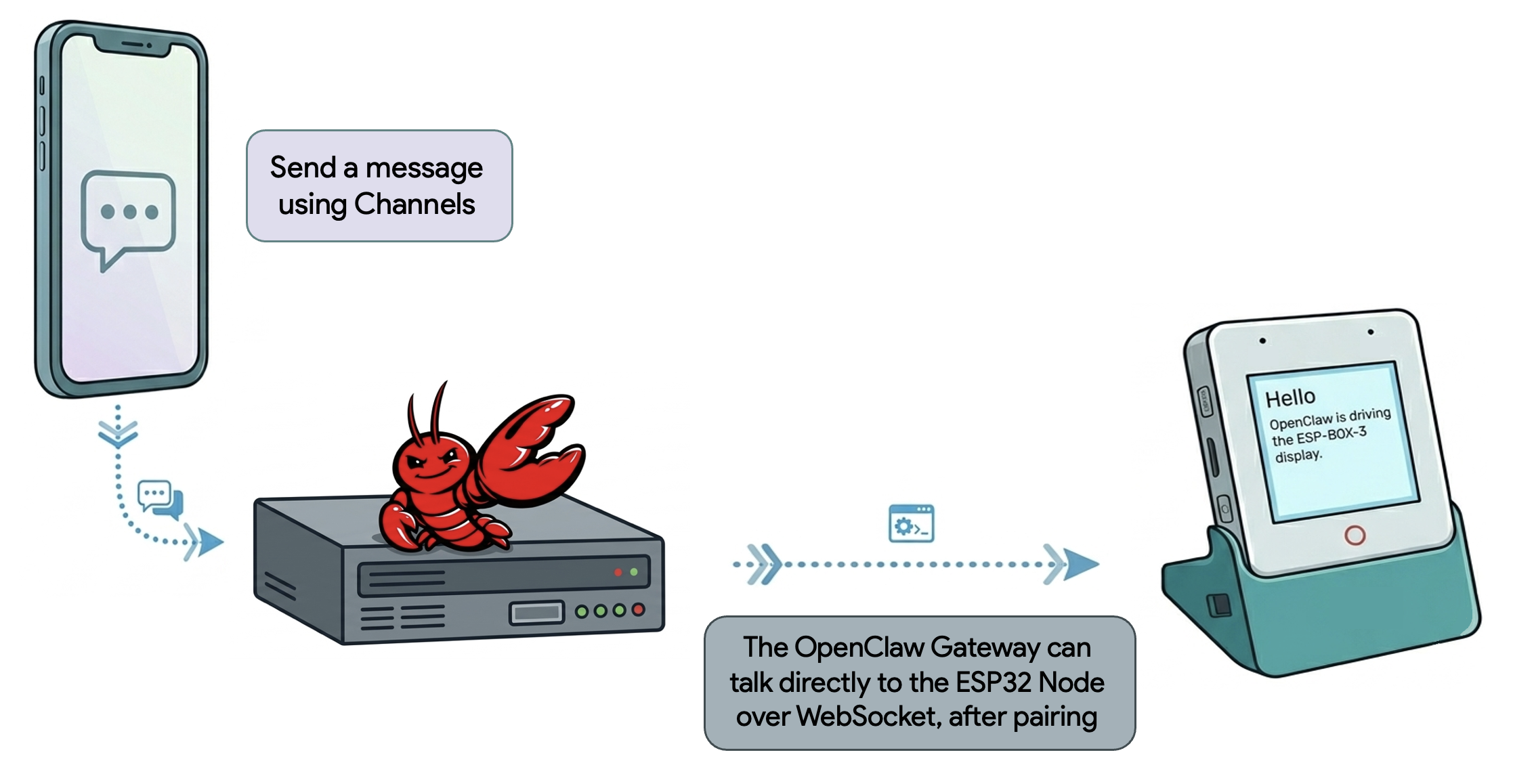
A r/LocalLLaMA thread asks what kind of machine is best for running local LLMs now that cloud-based coding copilots are getting expensive. The poster compares three common paths: a high-RAM Mac, a Windows PC with a high-end Nvidia GPU, and a compact workstation or mini supercomputer, and wants practical guidance on the tradeoffs between memory, speed, and cost.
// ANALYSIS
Hot take: for most people, the best local LLM box is the one that balances VRAM, RAM, and model size rather than the most expensive one on paper.
- –Macs with lots of unified memory are attractive for large models and simple setup, especially if you value quiet operation and macOS tooling.
- –Nvidia GPUs on Windows still win on raw throughput and ecosystem support, but VRAM is the real constraint; once you run out, performance drops off fast.
- –Small workstation-style systems can be convenient, but they are usually a compromise between portability and performance, not a universal best pick.
- –The key decision is what you want to run: small coding models, mid-sized chat models, or larger quantized models each push you toward different hardware.
// TAGS
local-firsthardwaregpumacwindowsvramunified-memoryinference
DISCOVERED
91d ago
2026-05-02
PUBLISHED
91d ago
2026-05-02
RELEVANCE
7/ 10
AUTHOR
attic0218