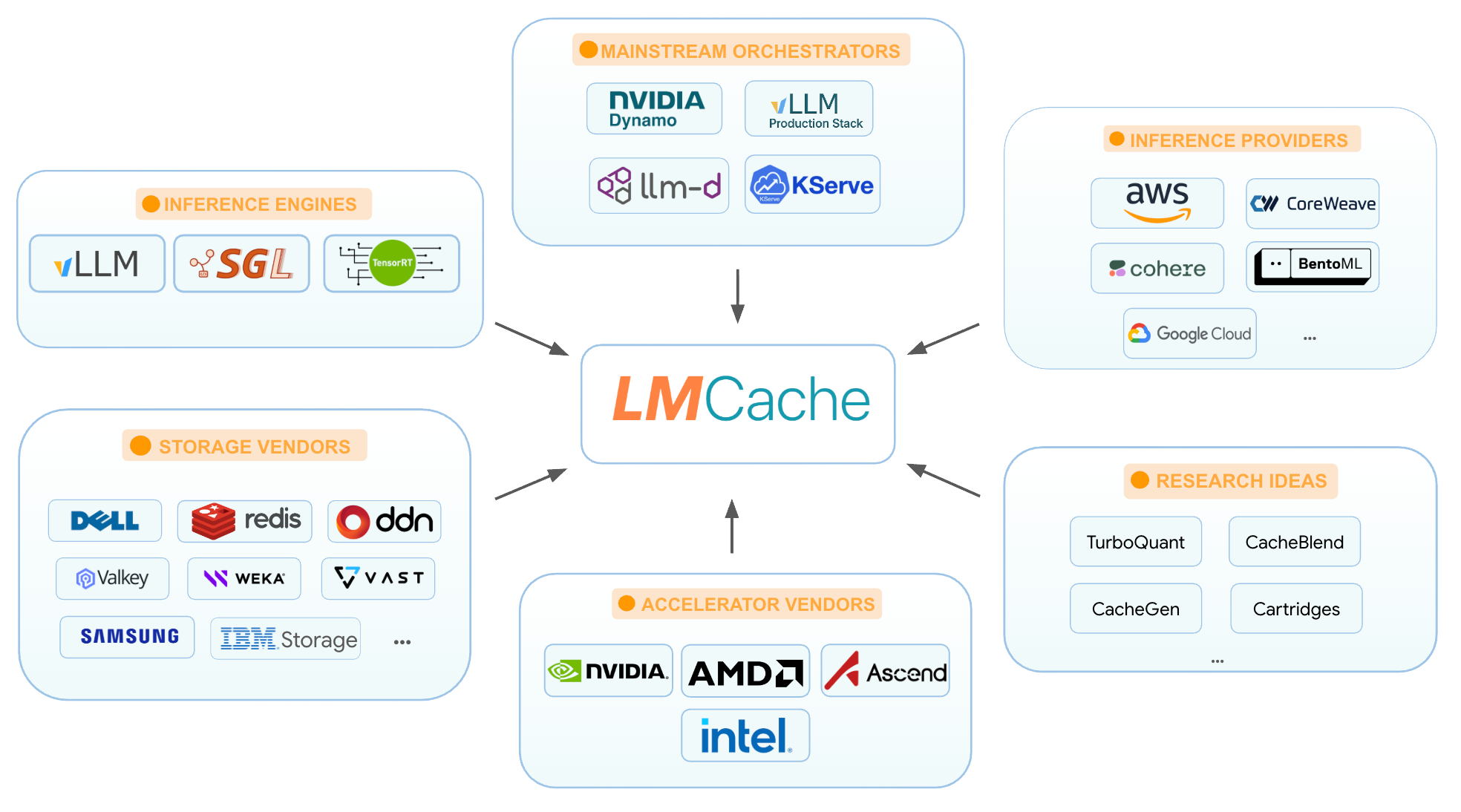
LMCache is an open-source KV cache management layer that supercharges LLM inference by sharing and reusing KV caches across GPUs, CPUs, and local/remote storage layers.
LMCache optimizes large language model (LLM) inference by extracting the Key-Value (KV) cache from GPU memory and treating it as a persistent, reusable asset rather than temporary, ephemeral data. By storing the KV cache across a tiered storage hierarchy—including CPU RAM, local disks, and remote backends like Redis or S3—LMCache enables prefix reuse across different queries, sessions, and physical machines. This decouples caching from the inference engine itself, offering integrations with popular platforms like vLLM and SGLang to drastically reduce Time-to-First-Token (TTFT) and boost serving throughput.
De-coupling the KV cache from serving engines is a logical evolutionary step for scaling LLM deployments, turning ephemeral GPU-bound state into a shared, tiered memory architecture.
* Decouples KV caching from the execution layer, allowing seamless integration with vLLM, SGLang, and other engines.
* Uses hierarchical storage (GPU, CPU, disk, cloud) to avoid GPU memory bottlenecks.
* Enables prefix reuse across physical servers and requests, eliminating redundant prefill computation.
* Particularly beneficial for workloads with long, repeating context, such as multi-turn chats, RAG, and document agents.
* Helps mitigate constraints on GPU memory capacity by introducing specialized compression and eviction policies.
DISCOVERED
45d ago
2026-06-13
PUBLISHED
45d ago
2026-06-13
RELEVANCE