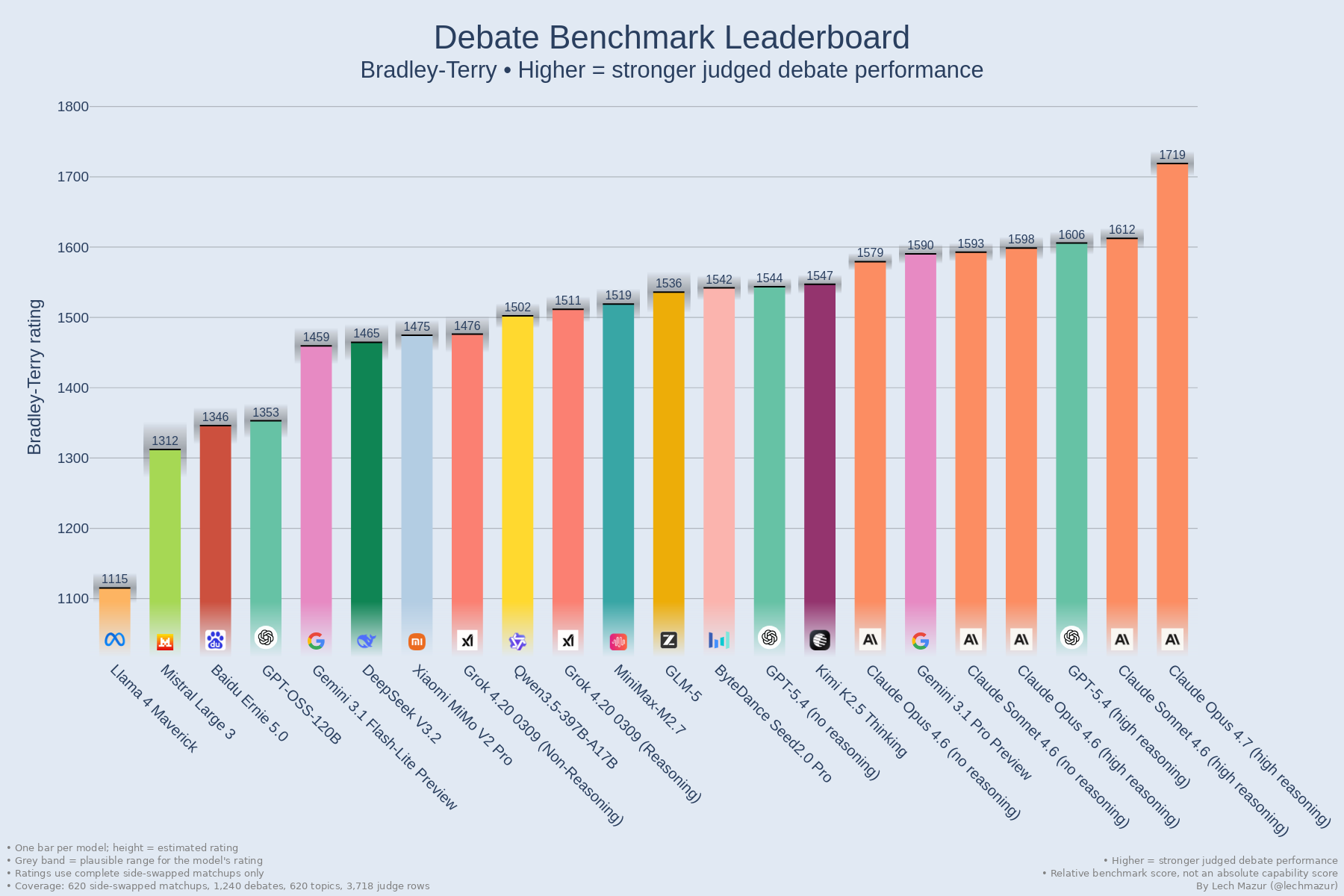
Opus 4.7 Tops LLM Debate Benchmark
The LLM Debate Benchmark has a new leader: Opus 4.7 (high) tops the leaderboard, beating the previous champion Sonnet 4.6 (high) by 106 BT points. The standout detail is its perfect completed side-swapped record so far, with 51 wins, 4 ties, and zero losses. The benchmark compares models by having them debate the same motion twice with sides swapped, then judging each completed debate with a three-model panel that avoids same-family judges.
The consistency matters more than the margin: a 51-4-0 record under side-swapped conditions suggests the model is controlling debate structure, not just phrasing. The side-swapped format reduces one-off framing advantages, and the three-model judging panel adds rigor, but the result still measures debate performance rather than broader general intelligence.
DISCOVERED
90d ago
2026-04-21
PUBLISHED
90d ago
2026-04-20
RELEVANCE
AUTHOR
zero0_one1