OPEN LINK ↗
// 45d agoBENCHMARK RESULT
DFlash hits 3X speedups on Google TPUs
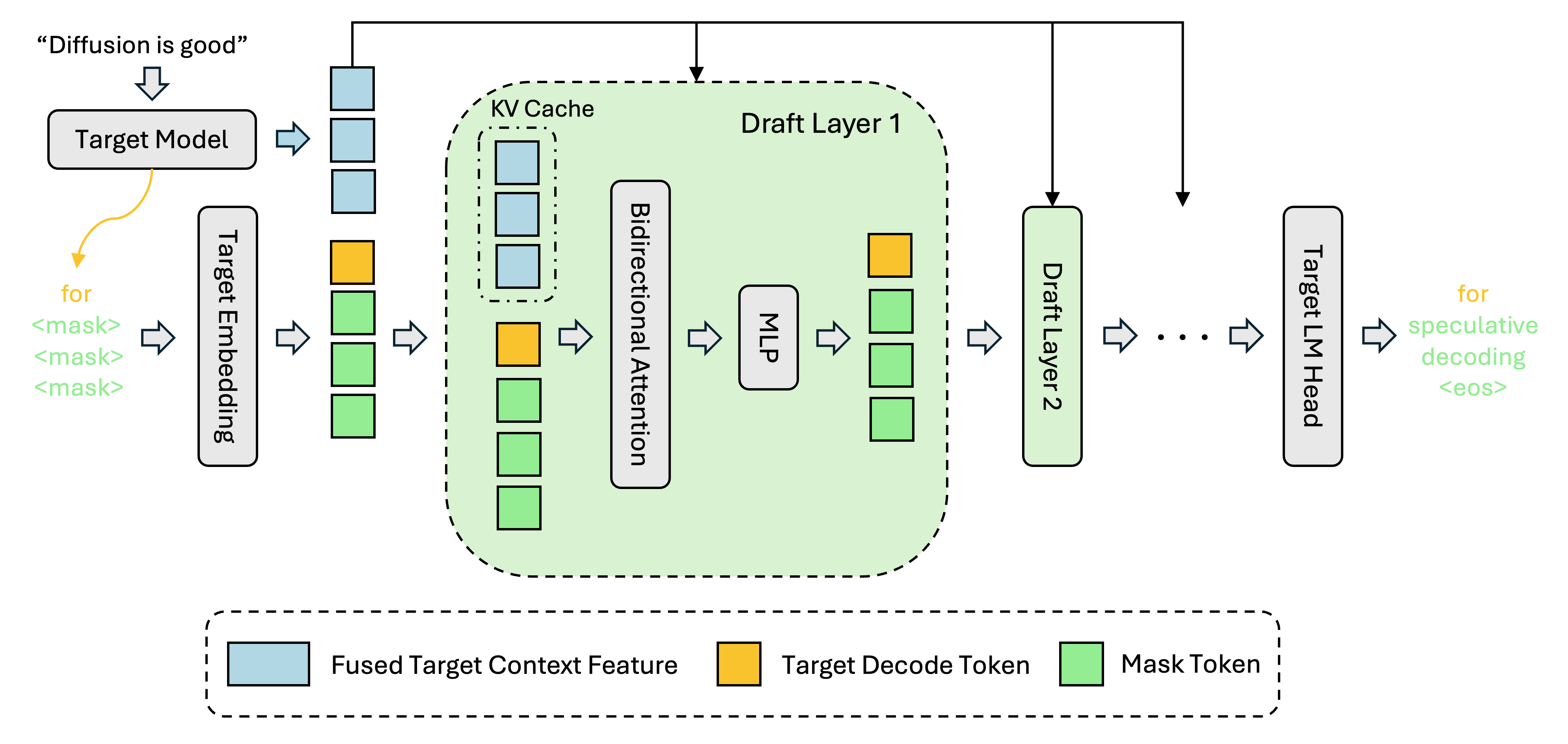
UCSD researchers ported DFlash block-diffusion speculative decoding to the vLLM TPU stack and reported a 3.13x average token-per-second gain on TPU v5p, with nearly 6x peaks on math workloads. Google is highlighting the work as an open-source milestone for TPU inference.
// ANALYSIS
This is a stronger signal for TPU serving than a single benchmark number suggests: the architectural shift matters because it removes the sequential drafting bottleneck that usually caps speculative decoding.
- –DFlash beat EAGLE-3 in the same TPU v5p setup, which makes the result more credible than a standalone microbenchmark
- –The biggest gains show up on math and coding, where output is more predictable and accepted draft blocks stay longer
- –The "K-flat" finding is the operational takeaway: wider draft blocks may be nearly free on datacenter TPUs, so draft quality becomes the real limiter
- –Shipping the implementation into vLLM TPU lowers adoption friction for teams already using that serving stack
- –This points to diffusion-style drafting as a serious next step for low-latency LLM inference, not just a research curiosity
// TAGS
dflashllminferencetpubenchmarkopen-sourceresearch
DISCOVERED
45d ago
2026-05-05
PUBLISHED
45d ago
2026-05-05
RELEVANCE
8/ 10
AUTHOR
eternviking