OPEN LINK ↗
// 90d agoMODEL RELEASE
Qwen3.6-35B-A3B strains RTX 4060 rigs
Qwen3.6-35B-A3B is Qwen’s new open-weight sparse MoE model with 35B total parameters and 3B active. On an RTX 4060 with 32GB RAM, it should be usable only with aggressive quantization and shorter contexts, not as a fast full-fidelity local model.
// ANALYSIS
Hot take: the model is efficient for its class, but the hardware ask is still real. The “3B active” headline helps, yet the 35B weight footprint and long-context design mean a single 8GB GPU is more of a compromise box than an ideal deployment target.
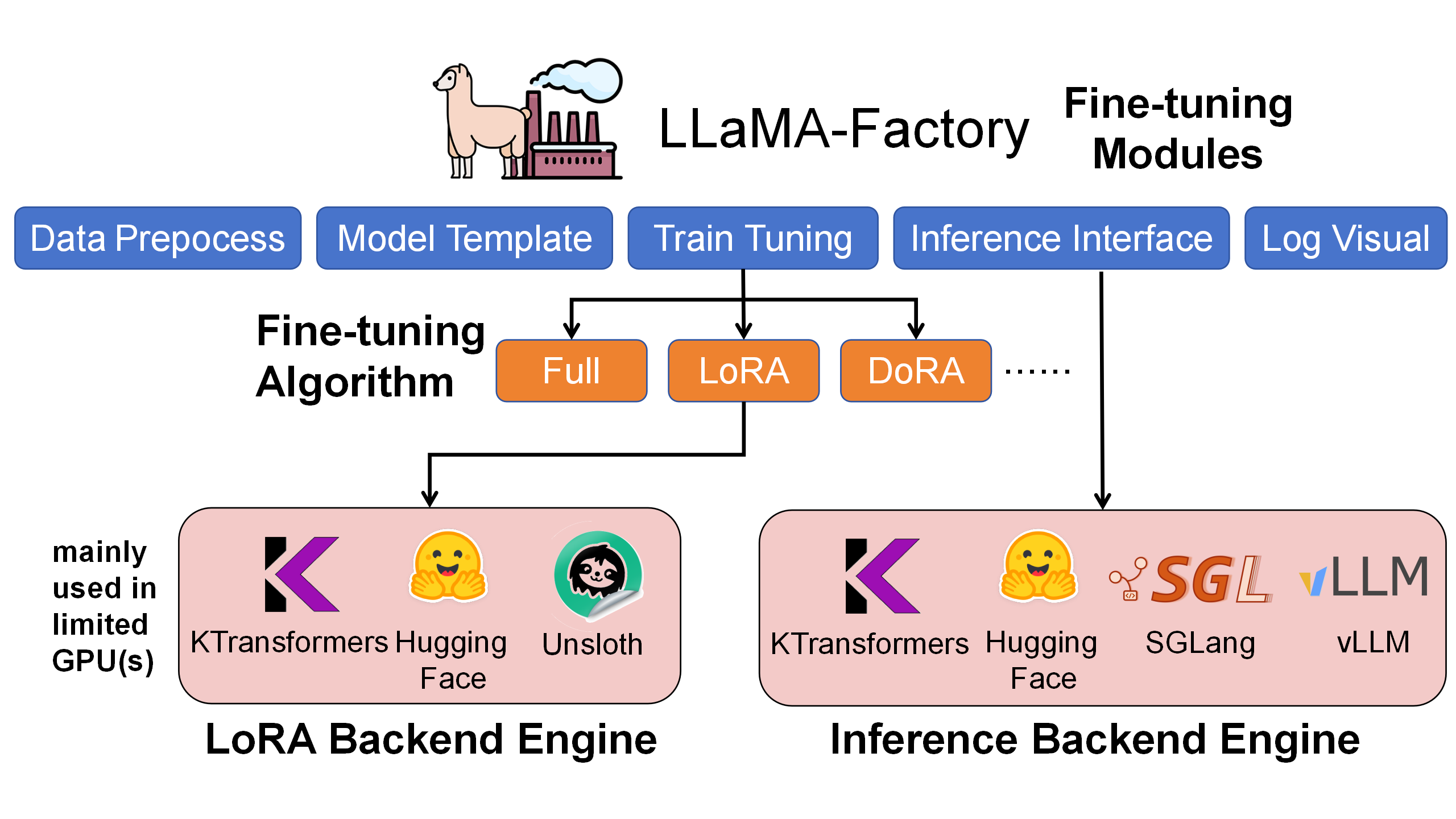
- –Official docs show Qwen3.6 targeting hosted APIs and multi-GPU serving paths, with 8-GPU tensor-parallel examples and a 262,144-token default context.
- –An RTX 4060 can likely run a quantized build with CPU offload, but speed and context length will be the first things to collapse.
- –The 32GB system RAM is the saving grace here; it gives you room for offload and larger KV cache, but it does not replace VRAM.
- –For daily local use, a smaller Qwen variant will feel much better; Qwen3.6-35B-A3B is more compelling if you care about capability per parameter than raw responsiveness.
- –Community reaction is already framing it as a serious open release, but also as a model that rewards better hardware and serving frameworks like vLLM, SGLang, or KTransformers.
// TAGS
qwen3.6-35b-a3bllmopen-sourcereasoningagentgpuself-hostedinference
DISCOVERED
90d ago
2026-04-20
PUBLISHED
90d ago
2026-04-19
RELEVANCE
9/ 10
AUTHOR
Extra-Perception2408