Yann LeCun introduces Temporal Difference in Vision
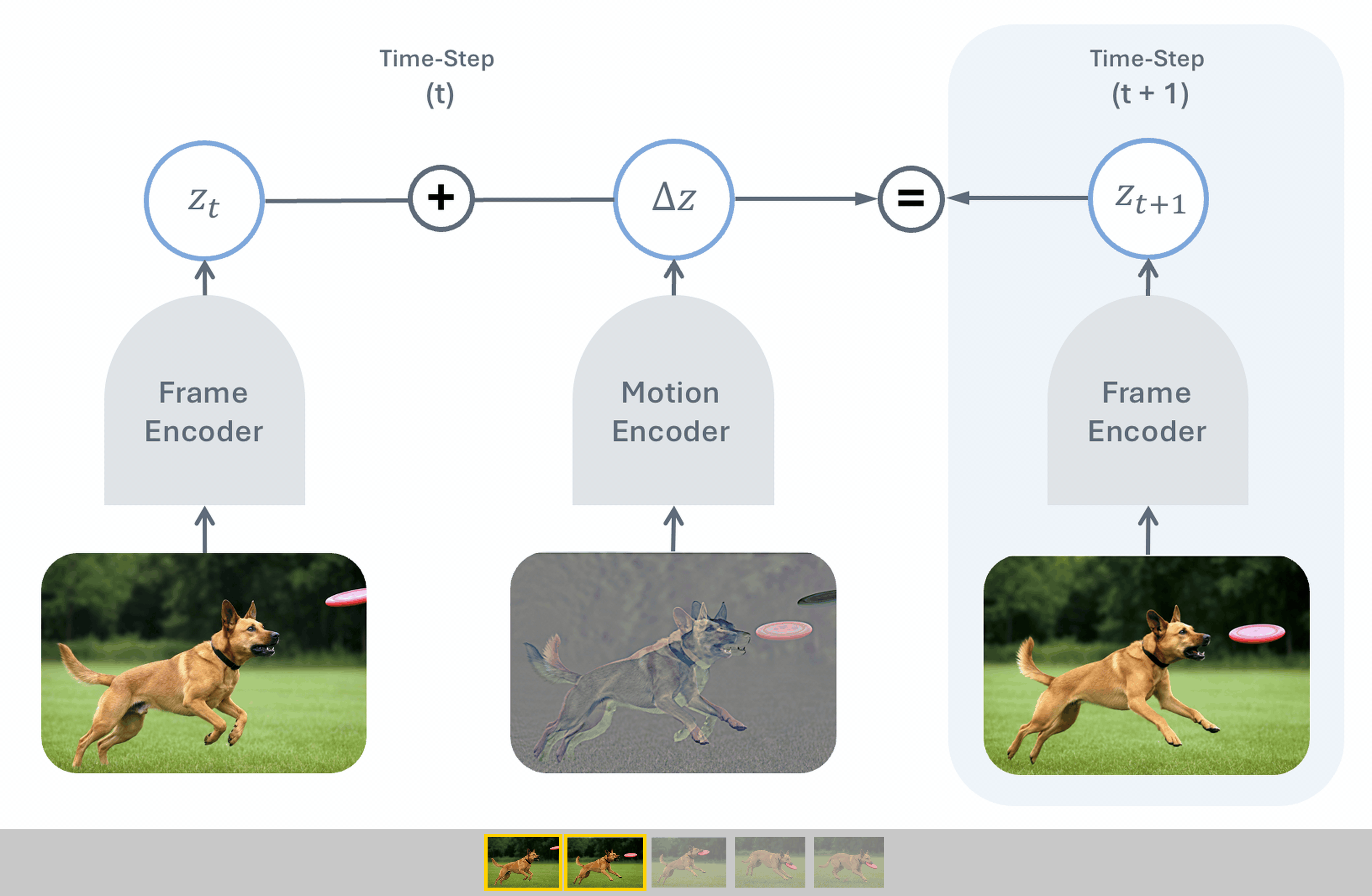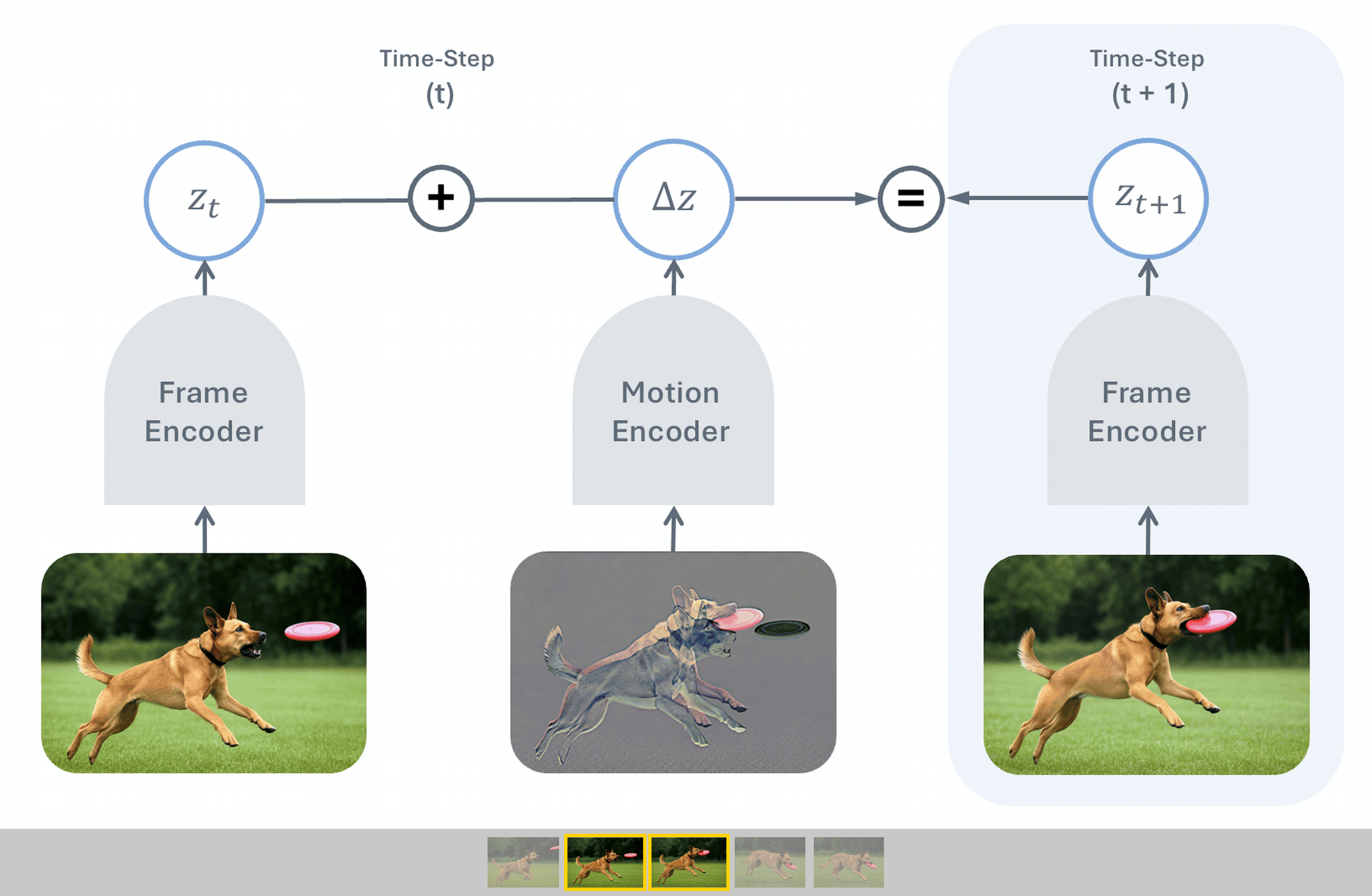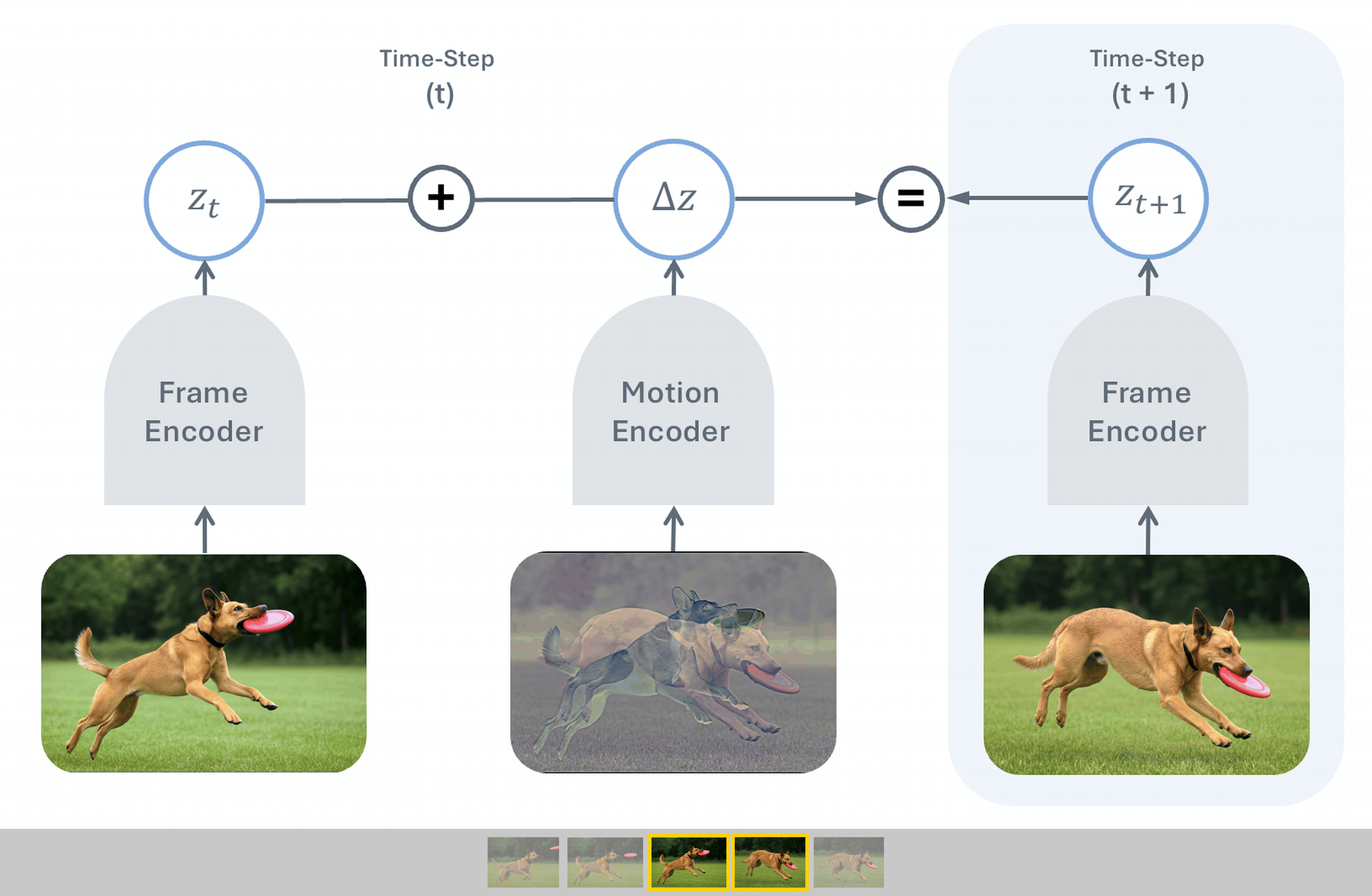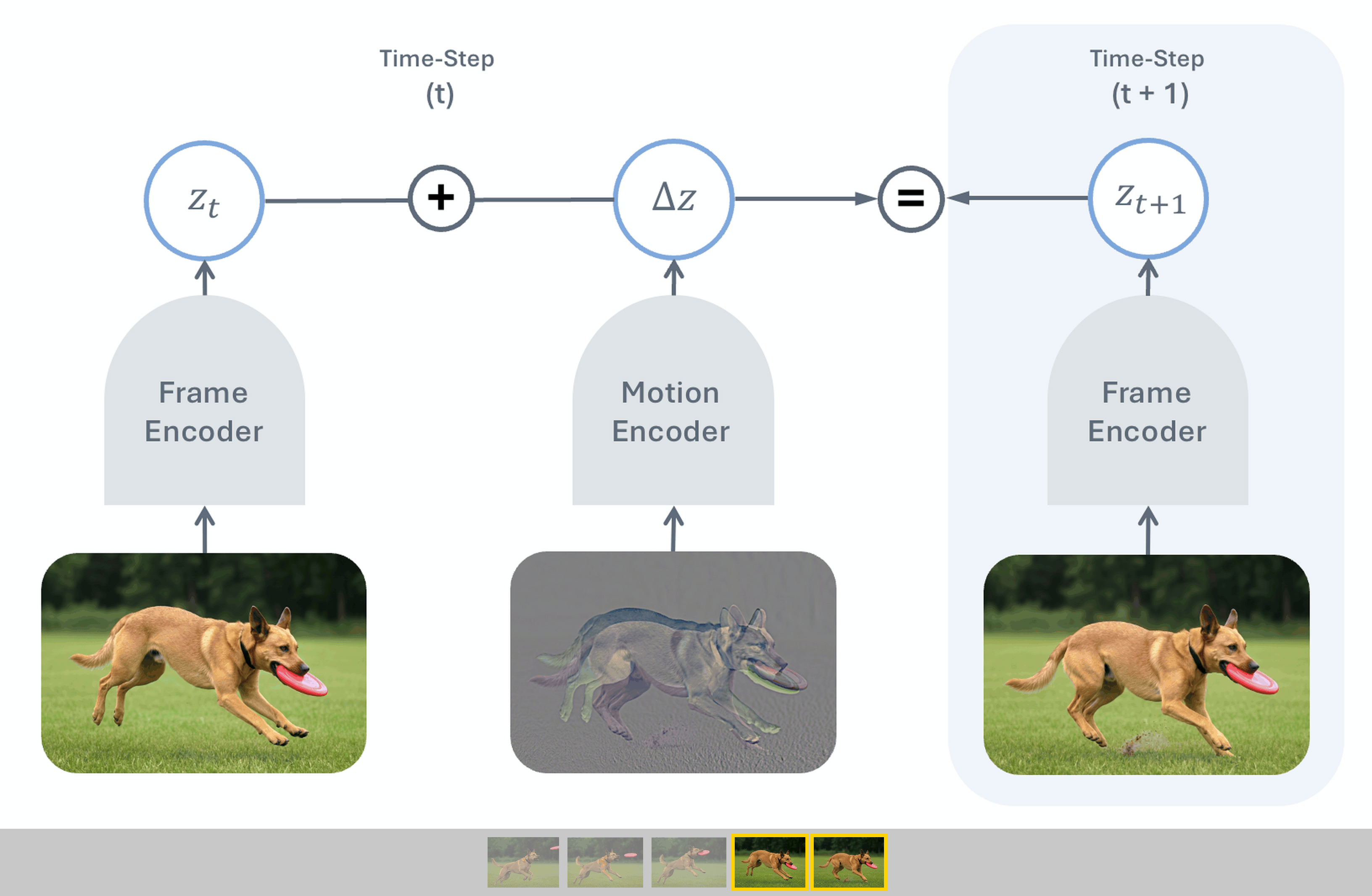
Temporal Difference in Vision (TDV) is a new self-supervised visual representation learning method co-authored by Yann LeCun that learns from video without traditional hand-engineered inductive biases like masking or cropping. By training an image encoder alongside a motion encoder to predict future frames using temporal differences, TDV achieves competitive performance on dense spatial tasks while scaling more effectively with larger datasets and compute.
While standard AI playbooks double down on complex, hand-designed supervision or data-augmentation tricks, TDV proves that simplifying assumptions is the real key to scaling visual models. By letting the temporal structure of video do the heavy lifting, it shifts the bottleneck from human design to compute availability.
- –Weaker Assumptions, Better Scaling: As dataset sizes increase, the need for restrictive inductive biases like image masking decreases, making simpler architectures more optimal.
- –Temporal Causal Principle: Moving from static-image self-supervised learning to predictive, time-based video modeling provides a more natural, domain-agnostic learning signal.
- –Stellar Dense Spatial Performance: Despite lacking explicit spatial contrastive training, TDV matches state-of-the-art methods in spatial understanding, showing the power of temporal differences.
DISCOVERED
45d ago
2026-06-16
PUBLISHED
45d ago
2026-06-16
RELEVANCE
AUTHOR
ylecun