Qwen 3.6-27B hits 5x speedup via DFlash
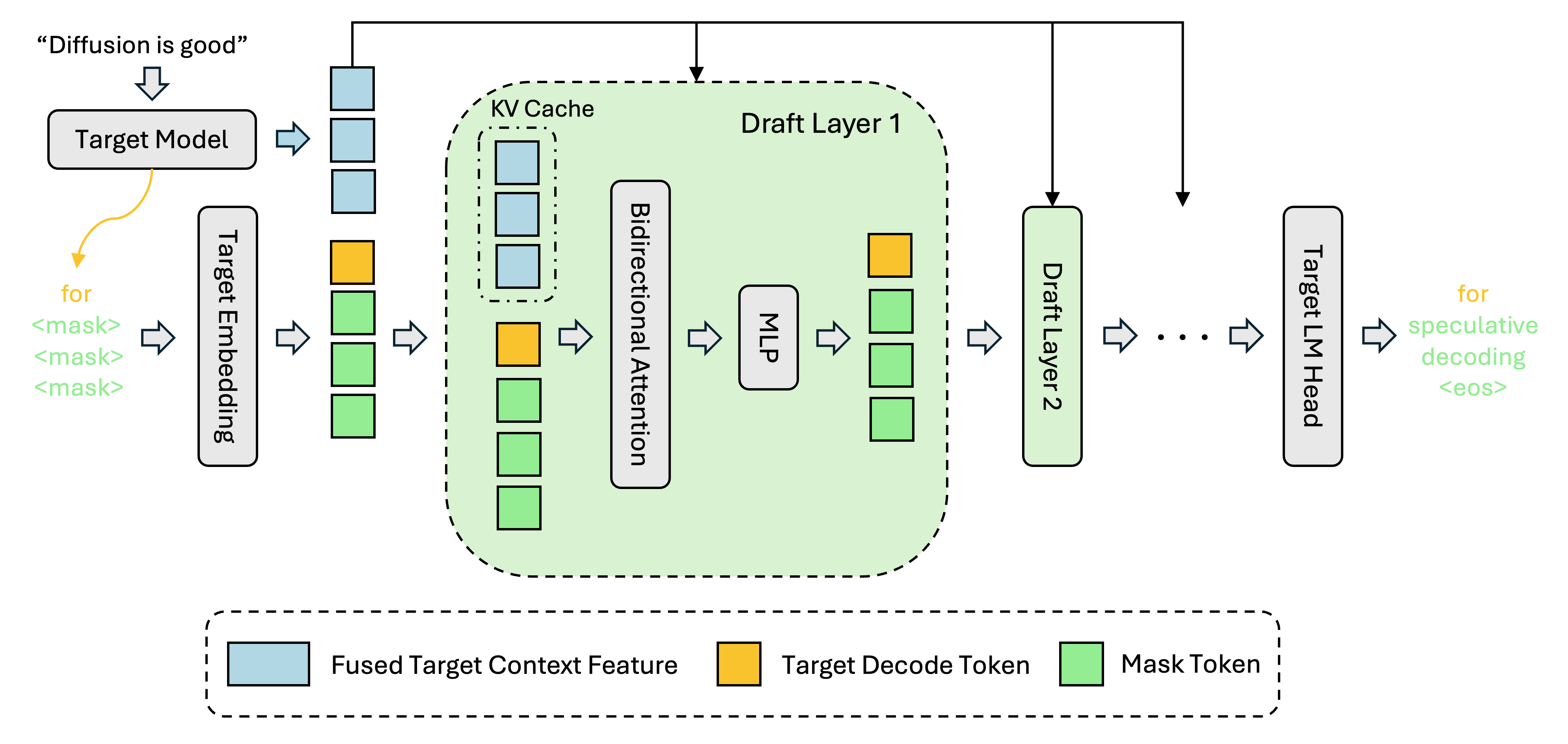
A new DFlash draft model optimized for Qwen 3.6-27B has been released, resolving the significant performance regressions seen when using older Qwen 3.5 speculators. This release enables high-speed speculative decoding for repository-level agentic coding tasks on local hardware.
Speculative decoding is shifting from a luxury to a requirement for local LLM viability, and the DFlash release for Qwen 3.6 is a critical infrastructure update. Architectural changes in Qwen 3.6, specifically Causal Sliding Window Attention (SWA), broke compatibility with older speculators, causing the "PP speed" issues reported by early adopters. The new model from Z-Lab bridges this gap, offering a 3x-5x throughput increase on consumer-grade GPUs like the RTX 4090. While Qwen 3.6 has native Multi-Token Prediction (MTP), the DFlash speculator remains the gold standard for high-performance inference in specialized engines like vLLM and SGLang. This release makes the 27B model's "agentic coding" and "Thinking Preservation" features truly real-time for local developers.
DISCOVERED
90d ago
2026-04-25
PUBLISHED
90d ago
2026-04-25
RELEVANCE
AUTHOR
butterfly_labs