OPEN LINK ↗
// 102d agoOPENSOURCE RELEASE
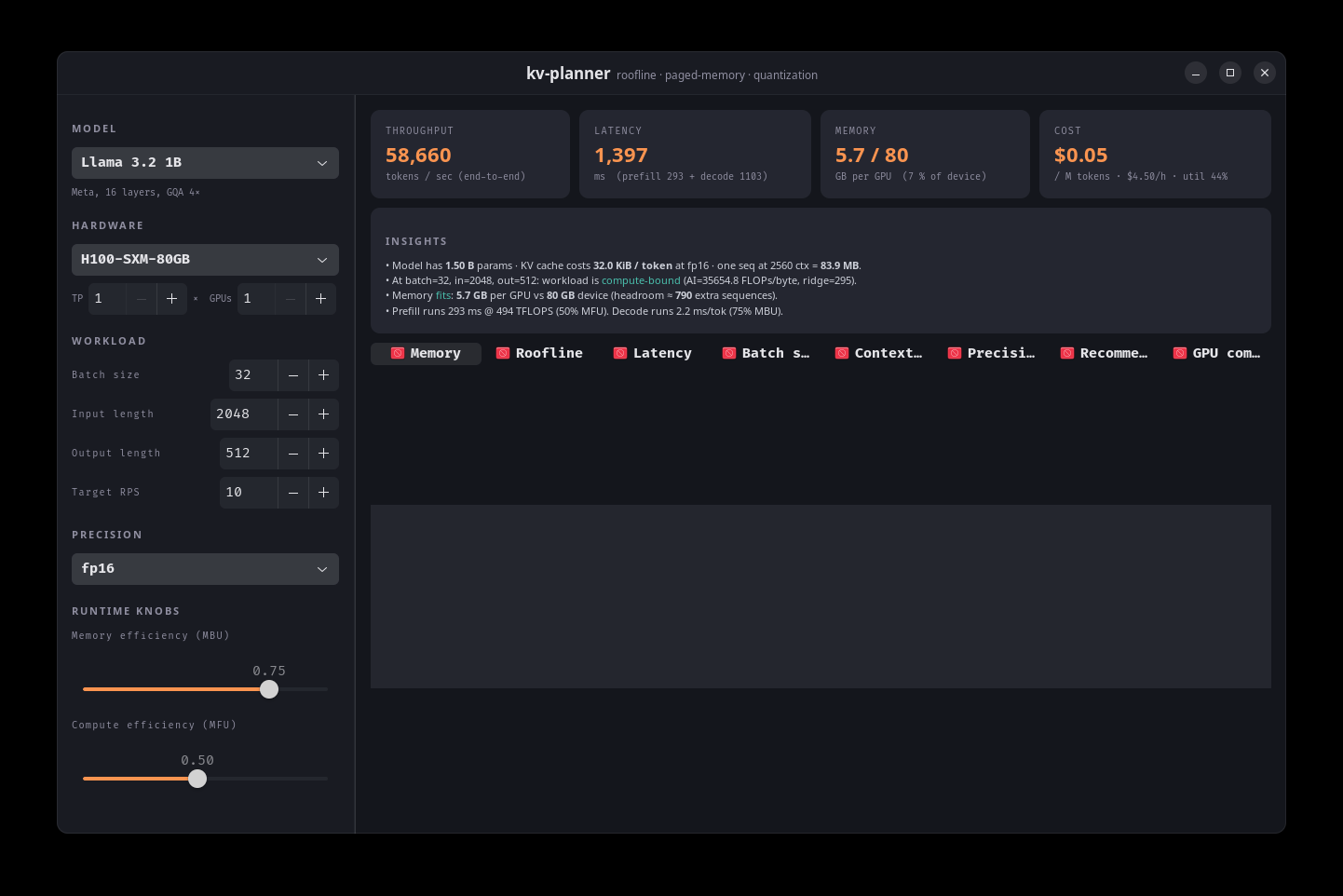
KV-planner sizes LLM GPU deployments
kv-planner is an MIT-licensed capacity planner for LLM inference that estimates GPU memory, latency, throughput, cost, KV cache usage, fleet sizing, speculative decoding, and reasoning-token overhead from physics-based formulas. The project now includes early real-hardware validation against vLLM on H100, A100, RTX 4090, and a MoE workload.
// ANALYSIS
This is a useful infrastructure tool because it attacks a real deployment pain point: the gap between datasheet math and runtime behavior.
- –Self-calibration is the strongest feature, since MBU/MFU defaults vary sharply across vLLM, Ollama, llama.cpp, consumer GPUs, and datacenter GPUs.
- –The MoE kernel-launch correction is a good reminder that active-parameter math alone misses scheduling overhead in modern inference stacks.
- –The validation story is promising but still thin; four GPUs and one MoE coefficient are not enough for production trust across MI300X, L40S, TensorRT-LLM, SGLang, or multi-node setups.
- –The broad interface surface, including CLI, GUI, REST, TUI, and MCP, makes it more than a spreadsheet replacement, but the project needs broader benchmark contributions to become a sizing reference.
// TAGS
kv-plannerinferencegpullmopen-sourcedevtoolbenchmarkmcp
DISCOVERED
102d ago
2026-04-21
PUBLISHED
102d ago
2026-04-21
RELEVANCE
8/ 10
AUTHOR
1Hesham