OPEN LINK ↗
// 45d agoBENCHMARK RESULT
OfficeQA Pro exposes enterprise reasoning gap
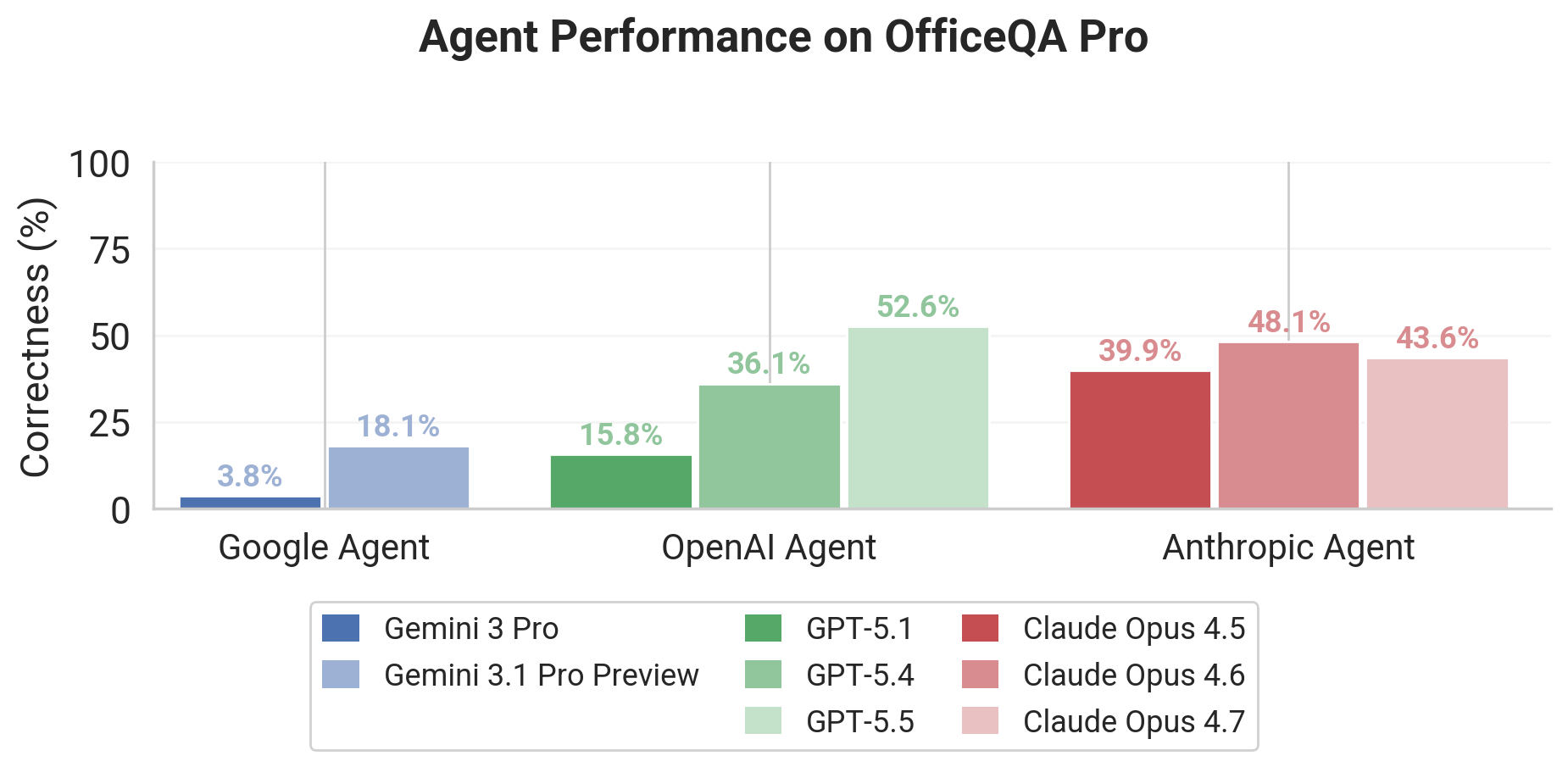
Databricks' OfficeQA Pro benchmark tests grounded, multi-document reasoning over 89,000 pages of U.S. Treasury Bulletins and 26 million numerical values. In the GPT-5.5 Databricks video, it serves as the proxy for realistic enterprise document workflows because even frontier models still leave substantial headroom on it.
// ANALYSIS
This is the kind of benchmark that matters because it punishes shallow pattern matching and forces models to do actual document work. The low ceiling is the point: it shows how far enterprise-grade grounded reasoning still has to go.
- –OfficeQA Pro is harder than typical QA suites because questions span dense PDFs, tables, retrieval, and numerical extraction across decades of documents
- –The reported gains from structured parsing suggest preprocessing quality can matter almost as much as raw model choice
- –Frontier models still struggle even with web access, which is a strong signal that public-web retrieval is not enough for closed, document-heavy workflows
- –For builders, the lesson is to optimize the full pipeline: OCR, structure extraction, retrieval, and answer validation
// TAGS
officeqa-probenchmarkreasoningllmsearchresearch
DISCOVERED
45d ago
2026-04-29
PUBLISHED
45d ago
2026-04-29
RELEVANCE
8/ 10
AUTHOR
OpenAI