OPEN LINK ↗
// 90d agoRESEARCH PAPER
MoDA paper adds depth-aware attention
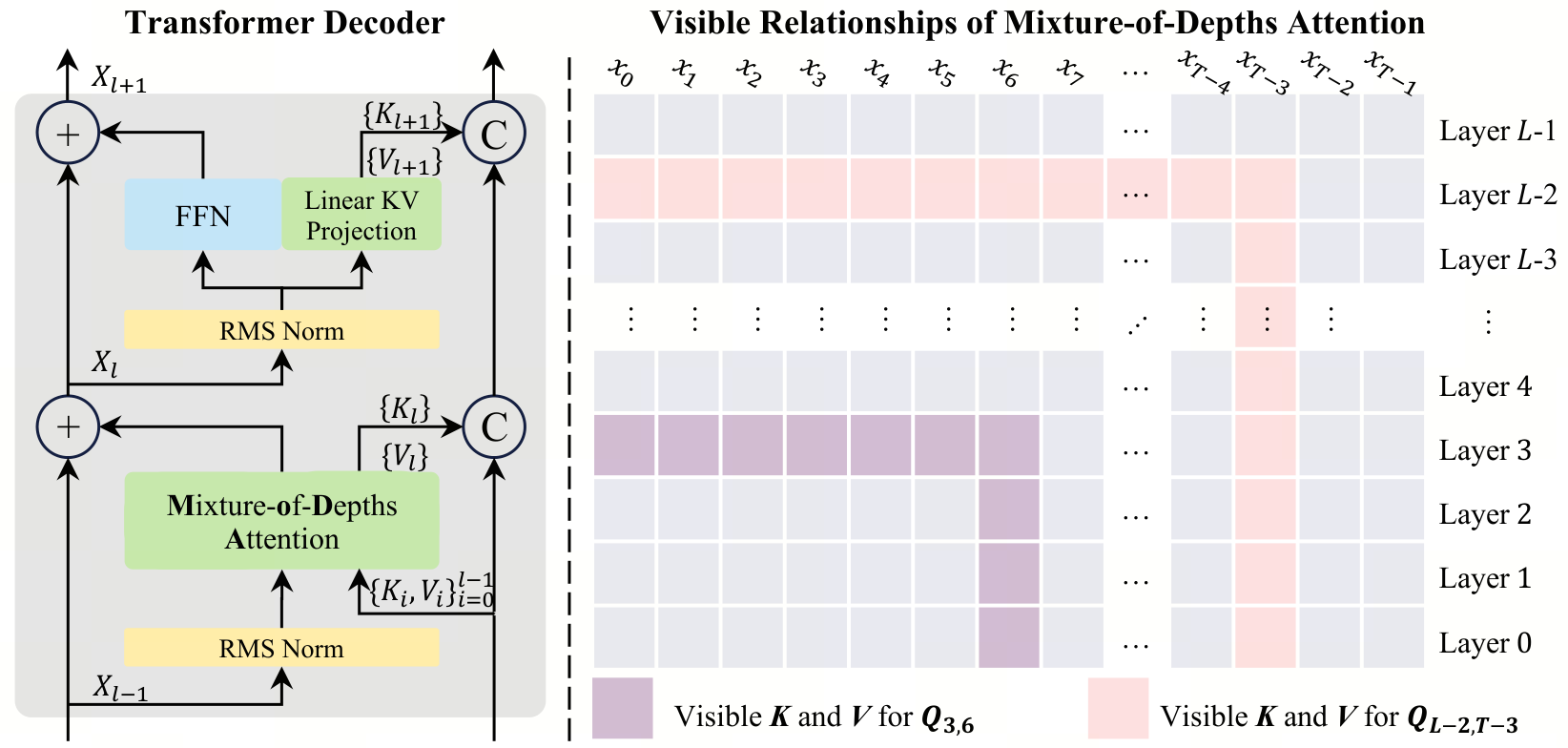
MoDA is a new attention mechanism that lets each head read both the current layer’s sequence KV pairs and depth KV pairs from earlier layers. The paper pairs that architecture with a hardware-aware implementation that stays close to FlashAttention-2 efficiency while improving perplexity and downstream task scores on 1.5B-parameter models.
// ANALYSIS
This is a strong architecture paper because it tackles both the modeling problem and the systems problem at the same time. The depth-retrieval idea is more interesting than another sparsity tweak, and the implementation story makes it credible for real training runs.
- –The core pitch is that deep transformers lose useful shallow signals; MoDA tries to preserve them by turning depth into a retrievable memory stream instead of relying on residual accumulation alone.
- –The reported numbers are meaningful for research: 97.3% of FlashAttention-2 efficiency at 64K, 3.7% FLOPs overhead, and consistent gains across validation and downstream benchmarks.
- –The post-norm vs pre-norm result matters because it suggests MoDA is not plug-and-play; architecture choices around normalization still shape the payoff.
- –The open-source repo and Triton kernels make this more than a paper-only idea, which increases the odds other teams will test or adapt it.
- –This feels most relevant to teams pushing long-context or deeper LLMs, where small efficiency losses are acceptable if they buy better depth information flow.
// TAGS
llmresearchopen-sourceinferencemoda
DISCOVERED
90d ago
2026-04-19
PUBLISHED
90d ago
2026-04-19
RELEVANCE
9/ 10
AUTHOR
pmttyji