OPEN LINK ↗
// 2h agoINFRASTRUCTURE
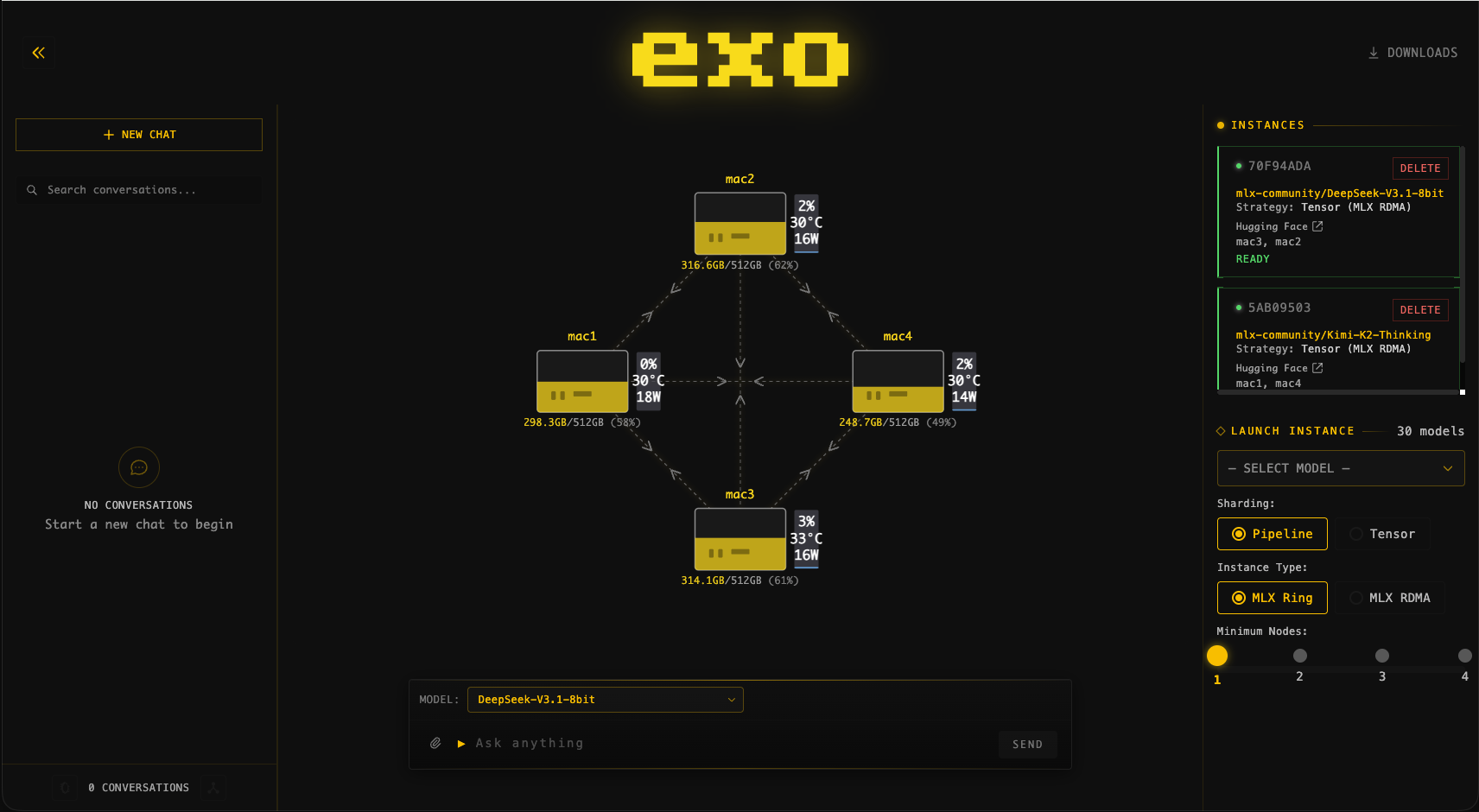
exo runs trillion-parameter model on Macs
A demonstration by developer @noisyb0y1 shows a trillion-parameter Mixture-of-Experts (MoE) model running at 25–28 tokens per second on a local cluster of four Apple Mac Studios. The setup utilizes the open-source exo framework built on Apple's MLX backend, daisy-chaining the Macs via Thunderbolt to pool their unified memory.
// ANALYSIS
Local distributed inference is reaching a tipping point where consumer-grade hardware clusters can challenge cloud-based enterprise GPUs for running massive, trillion-parameter sparse models.
- –Apple Silicon Advantage: Apple's unified memory architecture is the secret weapon for local AI, making large memory pools affordable compared to discrete enterprise GPUs.
- –Thunderbolt/RDMA Connectivity: Daisy-chaining Macs with low-latency interconnects removes traditional local networking bottlenecks.
- –Sparse MoE Architecture: Trillion-parameter models are only viable locally because they are sparse, activating only a fraction of parameters at runtime.
- –Enterprise Disruption: As local frameworks mature, smaller enterprises can run private, large-scale LLMs without ongoing cloud GPU subscriptions.
// TAGS
local-aiapple-siliconmac-studiodistributed-inferenceexomlxllm
DISCOVERED
2h ago
2026-06-19
PUBLISHED
2h ago
2026-06-19
RELEVANCE
8/ 10
AUTHOR
Av1dlive