Activation Lab maps LLM emotion layers
Activation Lab is an open-source interpretability harness for Hugging Face causal LLMs that captures per-layer activations, stores run data, and generates comparison reports and a Streamlit UI. Its debut experiment on Qwen2.5-3B argues that emotional signals stay legible deep into the stack and can be tracked with a small set of strategic hooks instead of full-model scans.
The interesting part is not the “AI has emotions” framing, but that a lightweight open-source tool is trying to turn activation tracing into something developers can actually run and inspect. The claims are provocative, but this is still closer to an interpretability demo plus hypothesis generator than settled science.
- –The repo packages a real workflow: scenario YAMLs, layer capture, comparison notebooks, heatmaps, logit lens tooling, and a Streamlit viewer instead of a one-off chart dump.
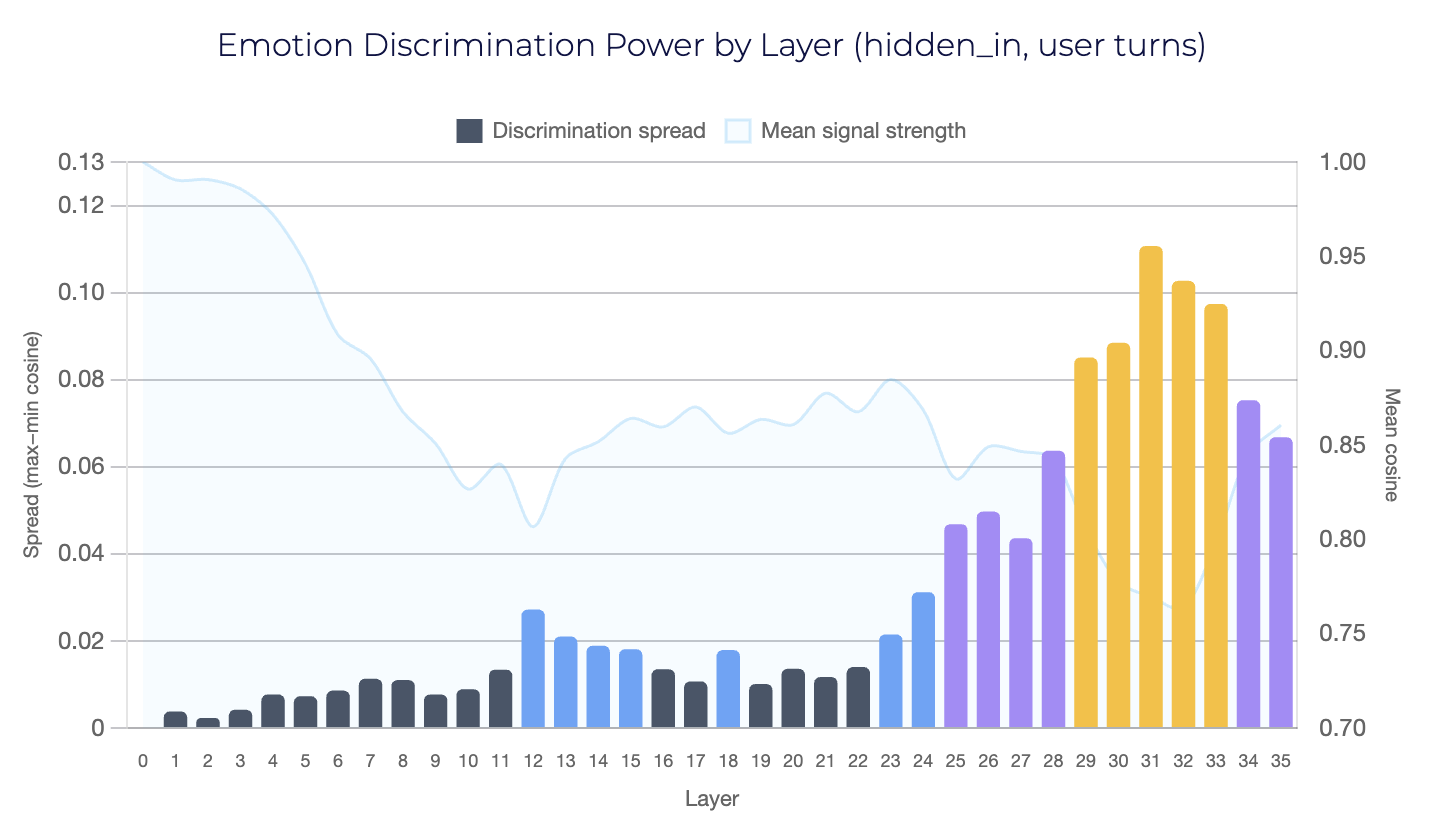
- –The strongest developer takeaway is efficiency: the author claims layers 2, 14, 23, 29-31, and 33 capture most of the useful emotion signal, which could make activation monitoring practical.
- –The “shock absorber” result is a useful framing for alignment work because it suggests instruction tuning may reshape internal geometry toward calm, not just output style.
- –The experiment is narrow: one model family, one emotion setup, and cosine comparisons to reference states, so generalization across architectures and prompts is still unproven.
- –If this line of work holds up, it points toward new debugging and safety tooling that watches what a model is internally representing, not only what it says.
DISCOVERED
90d ago
2026-04-23
PUBLISHED
90d ago
2026-04-23
RELEVANCE
AUTHOR
cstefanache