APEX quantization boosts Gemma 4 MoE performance
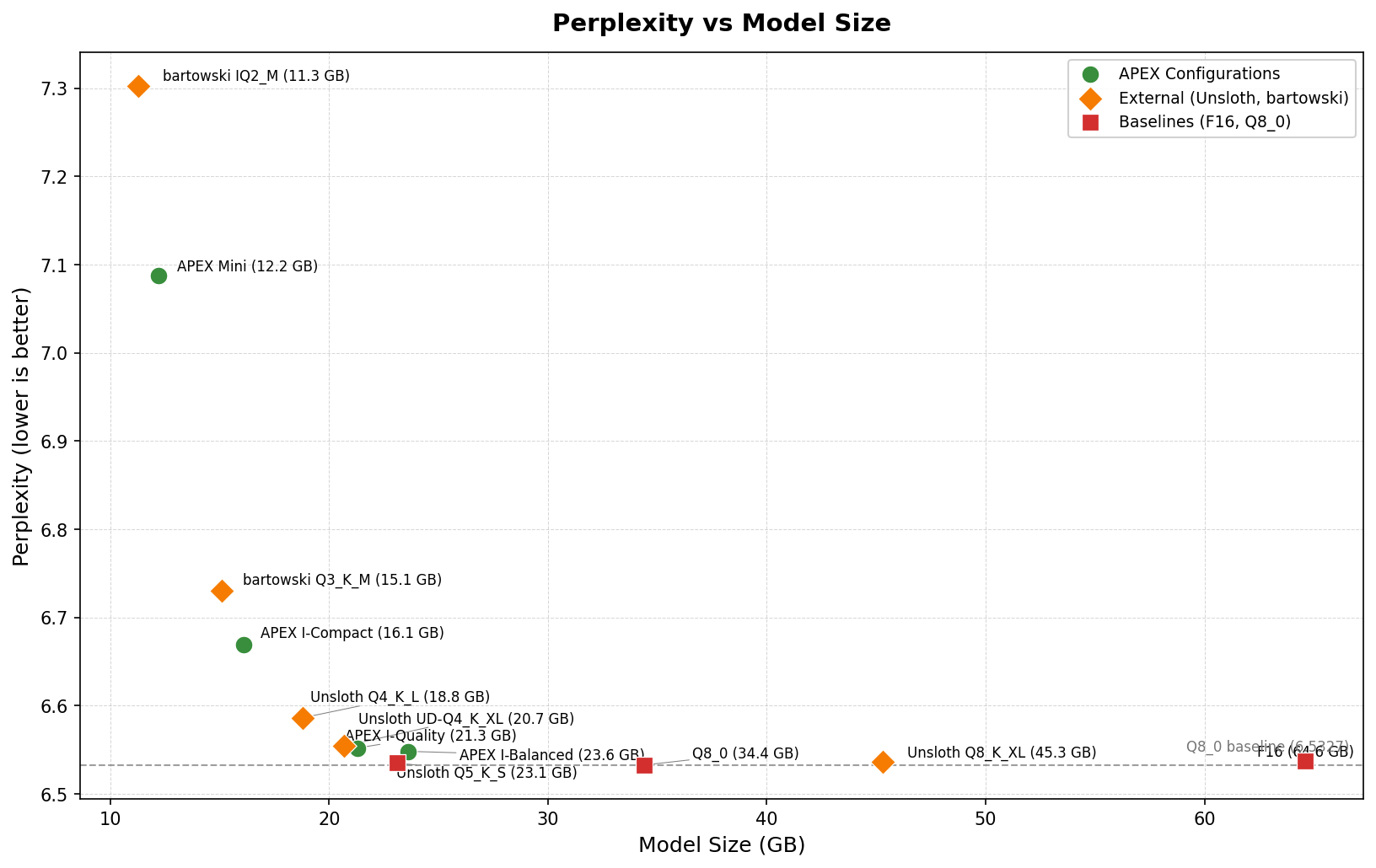
Developer mudler released APEX (Adaptive Precision for EXpert Models), a quantization format optimized for Mixture-of-Experts models like Google's Gemma 4. It achieves 38 tokens per second at a 90,000-token context window while solving long-context looping issues common in standard quants.
APEX quants represent a significant shift for sparse architectures, proving that uniform bit-width is inefficient for Mixture-of-Experts models. By protecting critical "edge" layers and shared experts while aggressively compressing redundant routed experts, this method allows 26B models to run with the speed and footprint of much smaller variants without sacrificing intelligence.
- –MoE Efficiency: Exploits sparse activation to fit 26B parameters into ~15GB of VRAM, ideal for 16GB consumer cards.
- –Context Stability: Demonstrates superior stability at 50k+ context compared to standard UD-Q5 quants, which often suffer from repetition loops.
- –Performance Sweet Spot: Delivers high-speed inference (38 tps) that makes large-scale local LLMs viable for real-time applications.
DISCOVERED
46d ago
2026-05-23
PUBLISHED
46d ago
2026-05-23
RELEVANCE
AUTHOR
Any-Chipmunk5480