OPEN LINK ↗
// 45d agoMODEL RELEASE
HRM-Text slashes pretraining compute, data
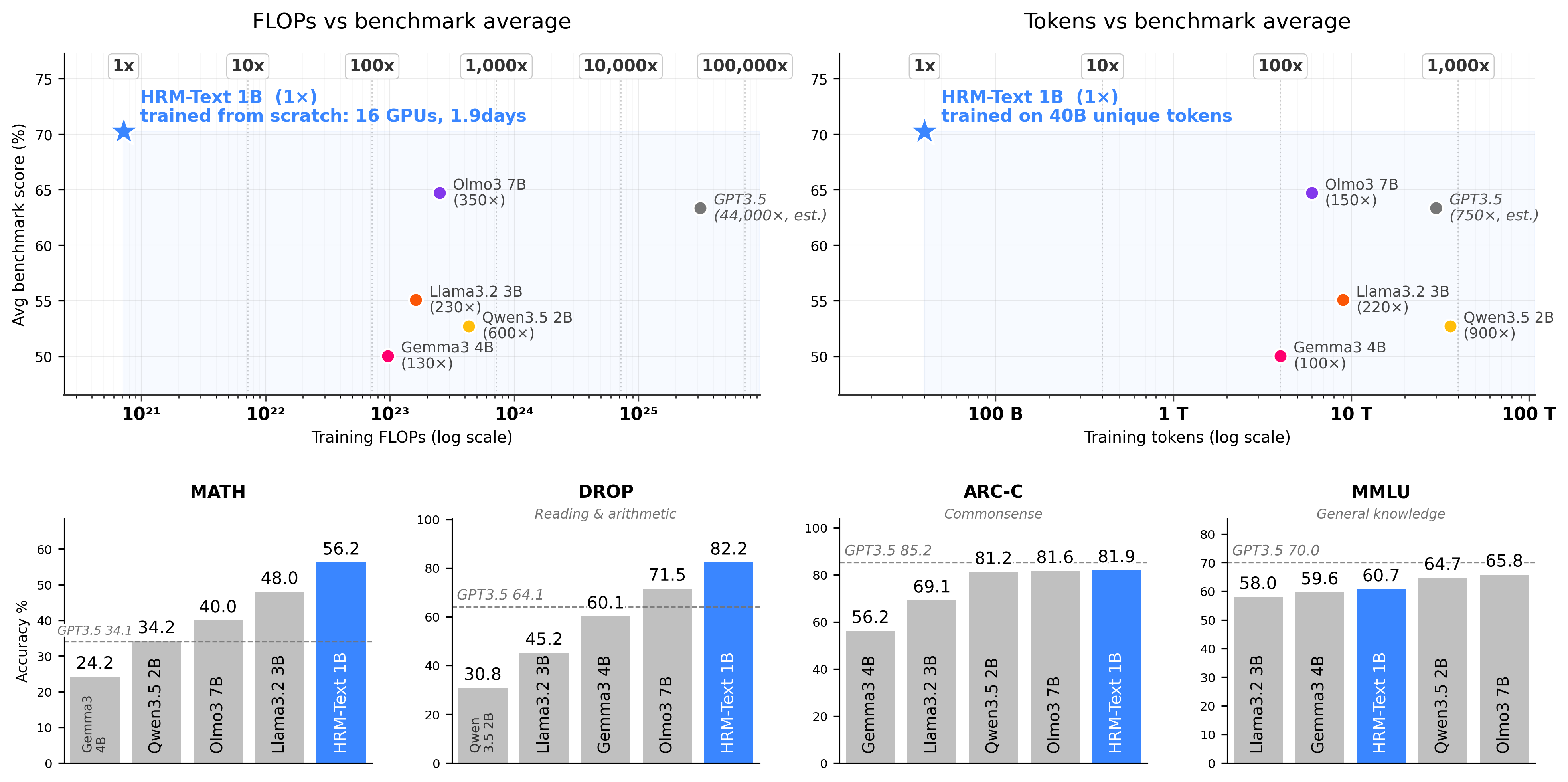
HRM-Text is a 1B text-generation model and training framework that swaps standard Transformers for a hierarchical recurrent architecture. The paper claims competitive benchmark results after training from scratch on 40B tokens with about $1,500 in compute.
// ANALYSIS
This is a serious efficiency claim, not just another architecture tweak: HRM-Text argues you can buy down pretraining cost by changing both the model and the objective, not by scaling harder.
- –The headline numbers matter: 60.7% MMLU, 81.9% ARC-C, 84.5% GSM8K, and 56.2% MATH from a 1B model trained on a relatively small budget
- –The repo packages the work as an end-to-end pretraining stack, with data sampling, FSDP2 training, evaluation, and checkpoint conversion, so it is meant to be reproduced, not just admired
- –The main novelty is architectural plus training-objective co-design: hierarchical recurrence, MagicNorm, deep credit-assignment warmup, and PrefixLM masking
- –If the results hold up outside the authors’ setup, this is a useful signal for labs that want controlled, cheaper pretraining runs rather than internet-scale brute force
- –The obvious caveat is that this is still a research result until broader replication and independent evals confirm the compute savings and quality tradeoffs
// TAGS
llmreasoningtrainingopen-sourceresearchhrm-text
DISCOVERED
45d ago
2026-05-21
PUBLISHED
45d ago
2026-05-21
RELEVANCE
9/ 10
AUTHOR
AlphaSignalAI