ztok delivers fast tokenizer parity in Zig
ztok is an open-source tokenizer toolkit in Zig 0.16 that loads existing tokenizer formats, aims for bit-identical parity with tiktoken, HuggingFace, and SentencePiece, and pushes performance with multithreaded encoding, SIMD byte scanners, and a stable C ABI. It supports byte-level BPE, Unigram, WordPiece, and TokenMonster-style tokenization, plus byte-accurate offsets for chunking/RAG workflows and bulk dataset tokenization. The project also ships eight language bindings and a sizable test suite, positioning it as a practical infrastructure library rather than a narrow benchmark toy.
Hot take: this is a serious systems-library release, not just another tokenizer wrapper. The main value is that it tries to collapse format fragmentation without sacrificing speed or parity.
- –Strong scope: one engine that can ingest `.tiktoken`, HF `tokenizer.json`, SentencePiece `.model`, Mistral Tekken, and TokenMonster-style vocabularies.
- –The parity claim matters more than the raw speed claim if it really holds across the supported formats, because it makes adoption much easier for existing pipelines.
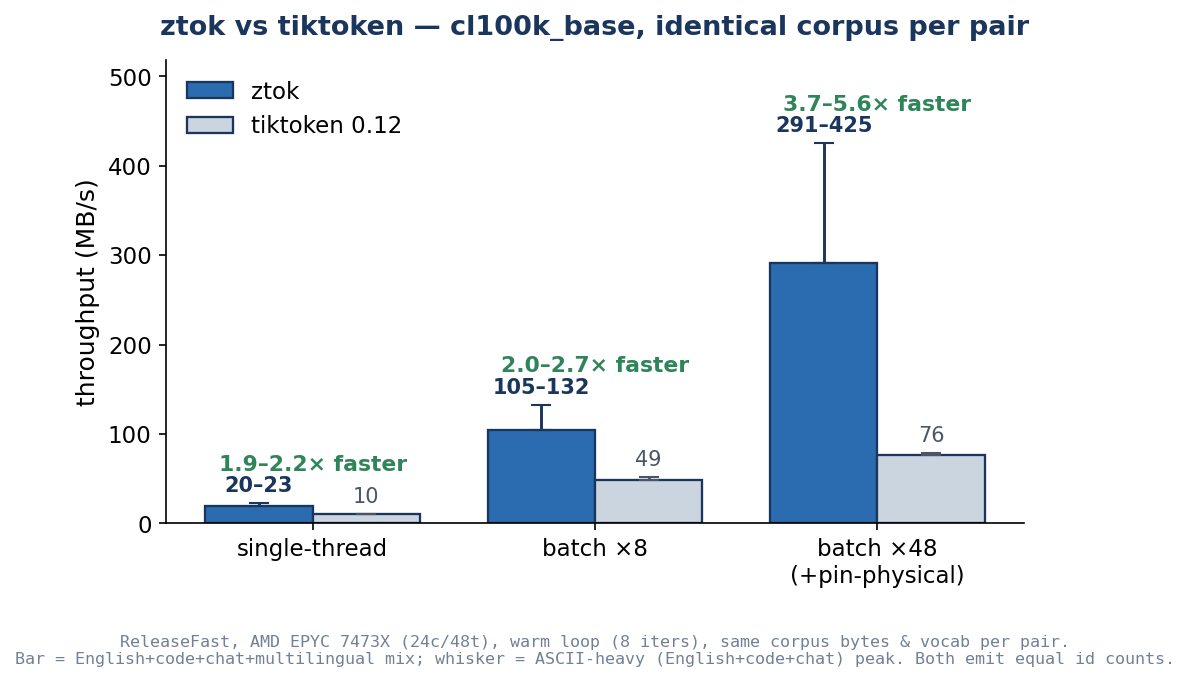
- –The performance pitch is credible on paper: multithreading, per-thread arenas, SIMD scanners, and a stable C ABI are the right ingredients for a throughput-focused tokenizer.
- –The product is clearly aimed at infrastructure users: RAG chunking with offsets, dataset preprocessing, fuzz-tested bindings, and format conversion are the useful parts.
- –The risk is complexity: supporting many tokenization families and round-tripping them all can create edge-case drift, so the test coverage and equivalence gates are the real story.
DISCOVERED
45d ago
2026-05-22
PUBLISHED
45d ago
2026-05-22
RELEVANCE
AUTHOR
FaustAg