OPEN LINK ↗
// 90d agoTUTORIAL
Speculative decoding repo compares proposer strategies
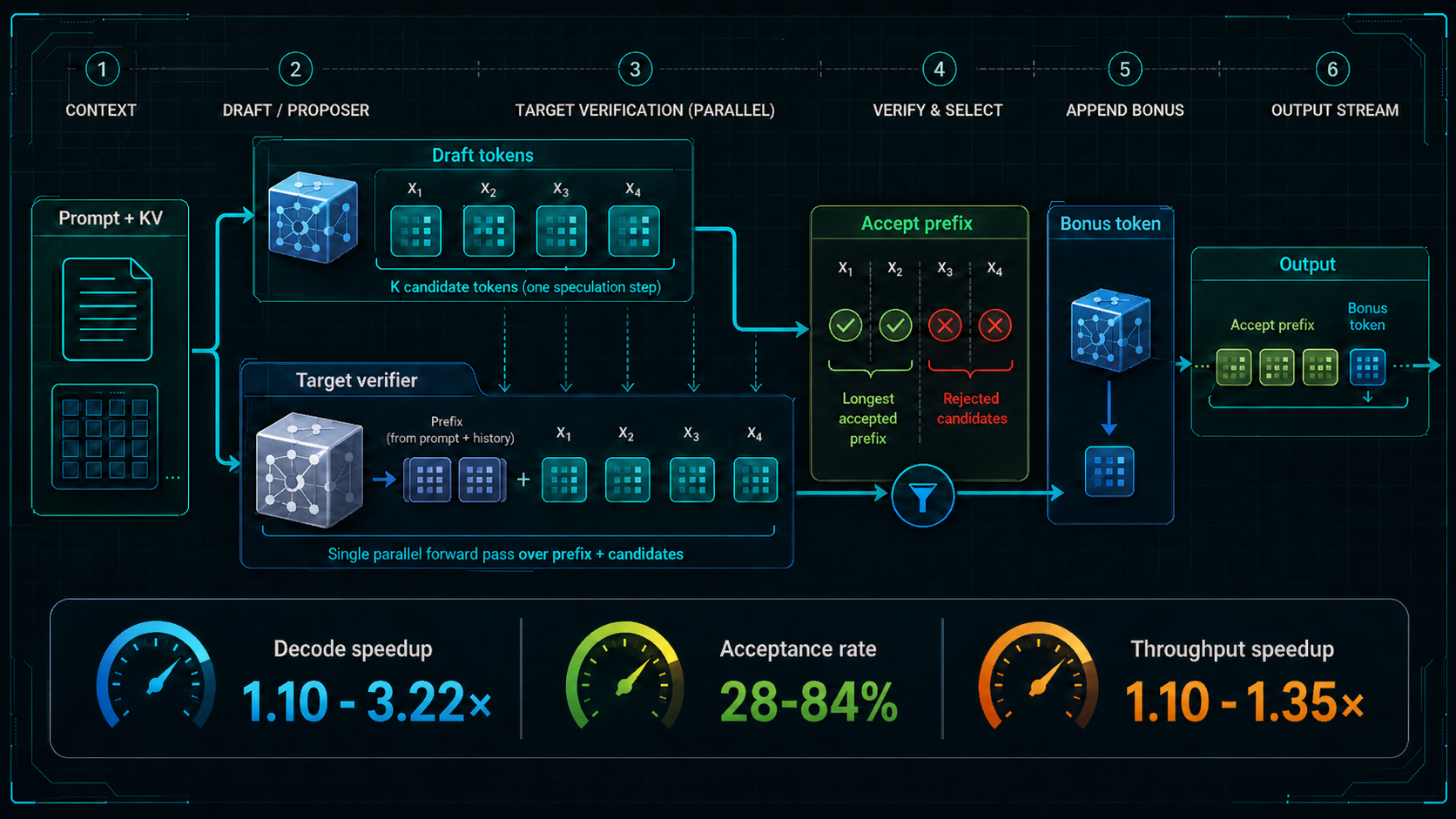
This open-source educational repo implements multiple speculative decoding approaches from scratch, including EAGLE-3, Medusa-1, standard draft-model speculation, PARD, n-gram prompt lookup, and suffix decoding. It is structured to make proposer training, draft generation, target verification, caching, and throughput tradeoffs easy to study side by side, with both training and inference paths where applicable.
// ANALYSIS
Hot take: this is most valuable as a systems explainer, not just a speed benchmark. It shows that speculative decoding performance is determined by the whole proposer-verifier pipeline, not by acceptance rate alone.
- –The shared contract makes it easier to compare proposer quality, verifier cost, and acceptance behavior across very different methods.
- –Learned heads like EAGLE-3 and Medusa-1 are fundamentally different from draft-model speculation because they attach speculation to internal model representations instead of relying on a separate smaller LM.
- –PARD is a good reminder that lower acceptance can still win if proposer generation is cheap enough and parallelism is better utilized.
- –N-gram and suffix decoding are useful baselines because they expose how far training-free reuse can go when prompts have repeated structure.
- –The repo’s small-slice benchmarks are best treated as implementation evidence and workflow intuition, not broad throughput claims.
// TAGS
speculative decodingllm inferenceeagle-3medusa-1parddraft modelsn-gram decodingsuffix decodingopen sourcetutorial
DISCOVERED
90d ago
2026-04-26
PUBLISHED
90d ago
2026-04-26
RELEVANCE
9/ 10
AUTHOR
shreyansh26