MiniMax open-sources MSA sparse attention kernel
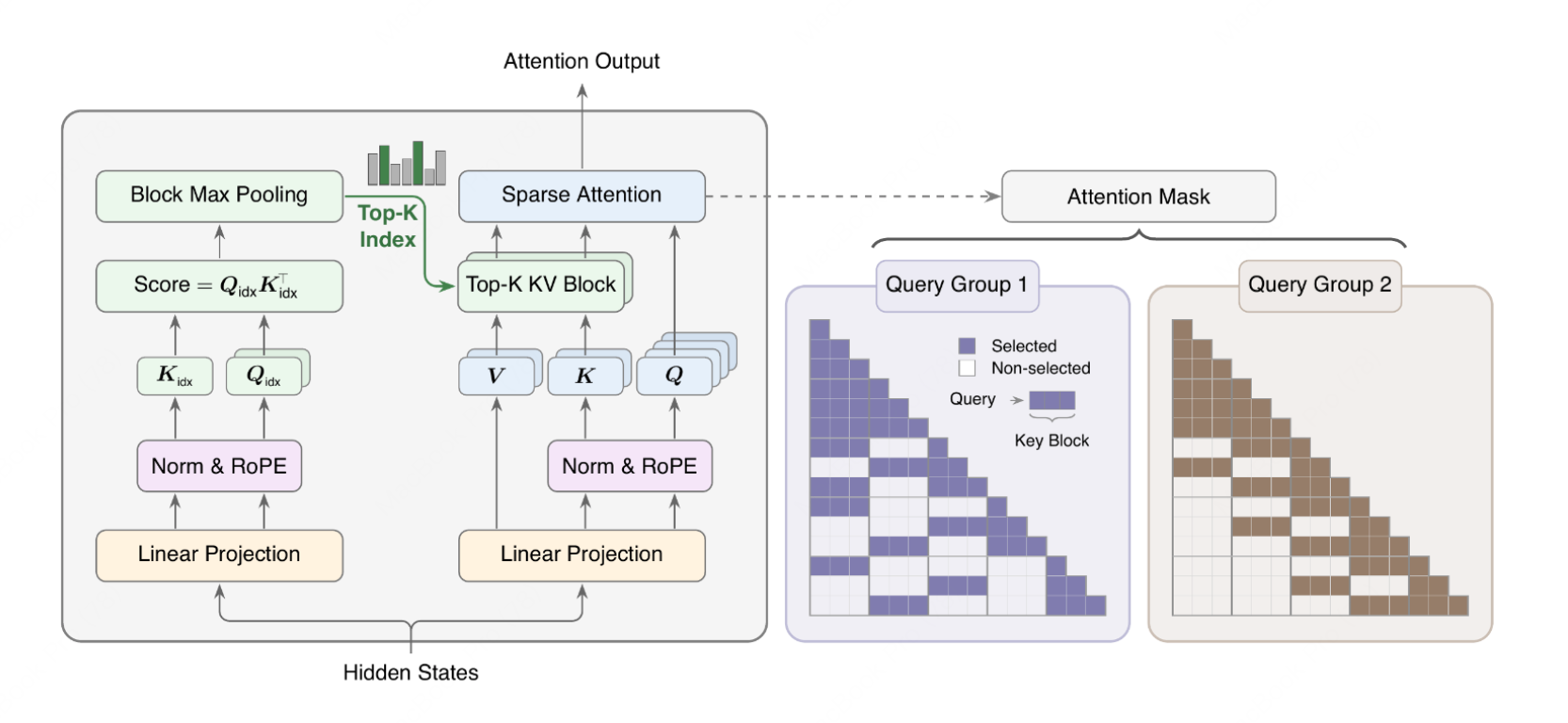
MiniMax has open-sourced MiniMax Sparse Attention (MSA), a blockwise sparse attention kernel designed to handle million-token context windows efficiently. By combining a two-branch architecture with a co-designed GPU execution path, MSA reduces per-token compute by 28.4×, achieving a 14.2× prefill speedup and 7.6× decoding speedup on H800 GPUs.
MiniMax's MSA demonstrates that combining algorithmic sparsity with hardware-level co-design is key to deploying million-token context models without prohibitive hardware costs. Decoupled indexing uses a lightweight branch to run low-dimensional projection and Top-k selection, avoiding the quadratic bottleneck of dense attention. Hardware co-design featuring exp-free Top-k selection and KV-outer sparse attention ensures high Tensor Core utilization. Finally, integration into the MiniMax-M3 multimodal model shows the kernel is battle-tested and ready for production scaling.
DISCOVERED
45d ago
2026-06-14
PUBLISHED
45d ago
2026-06-14
RELEVANCE
AUTHOR
Github Awesome