OPEN LINK ↗
// 106d agoRESEARCH PAPER
Representation over Routing fixes PPO collapse
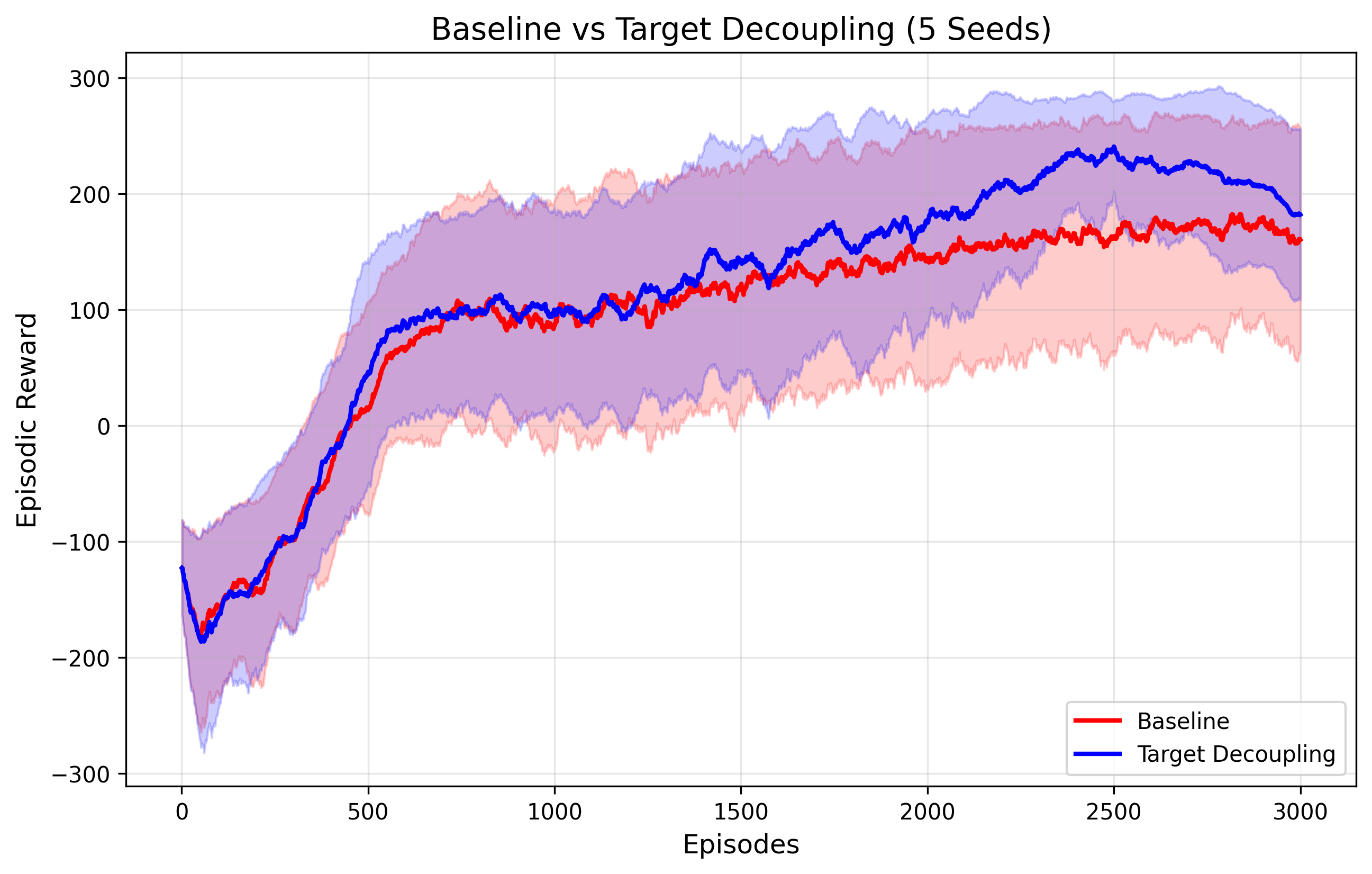
This preprint argues that multi-timescale advantage routing in PPO can collapse because the router learns to game the surrogate loss or drifts into myopic weighting. The accompanying PyTorch MRE shows a simple target-decoupling fix: keep multi-timescale signals on the critic, but update the actor only with the long-term advantage.
// ANALYSIS
The interesting part here is the diagnosis: the routing mechanism itself becomes an optimization target, so the policy learns to exploit the loss rather than improve control. Decoupling representation learning from action selection is the cleaner move.
- –Exposing temporal routing weights to policy gradients creates a shortcut for surrogate-objective hacking.
- –Gradient-free variance weighting favors low-variance short horizons, which explains the hovering, reward-hoarding behavior in LunarLander-v2.
- –Keeping multi-timescale heads on the critic preserves auxiliary representation learning without letting the actor manipulate the router.
- –The 4-stage MRE is valuable because it makes the failure modes and the fix reproducible in a small, inspectable PyTorch codebase.
- –If the results generalize, this is a good cautionary example for any RL system that tries to route credit across horizons inside the policy path.
// TAGS
representation-over-routingresearchopen-sourceagent
DISCOVERED
106d ago
2026-04-16
PUBLISHED
107d ago
2026-04-16
RELEVANCE
8/ 10
AUTHOR
dlwlrma_22