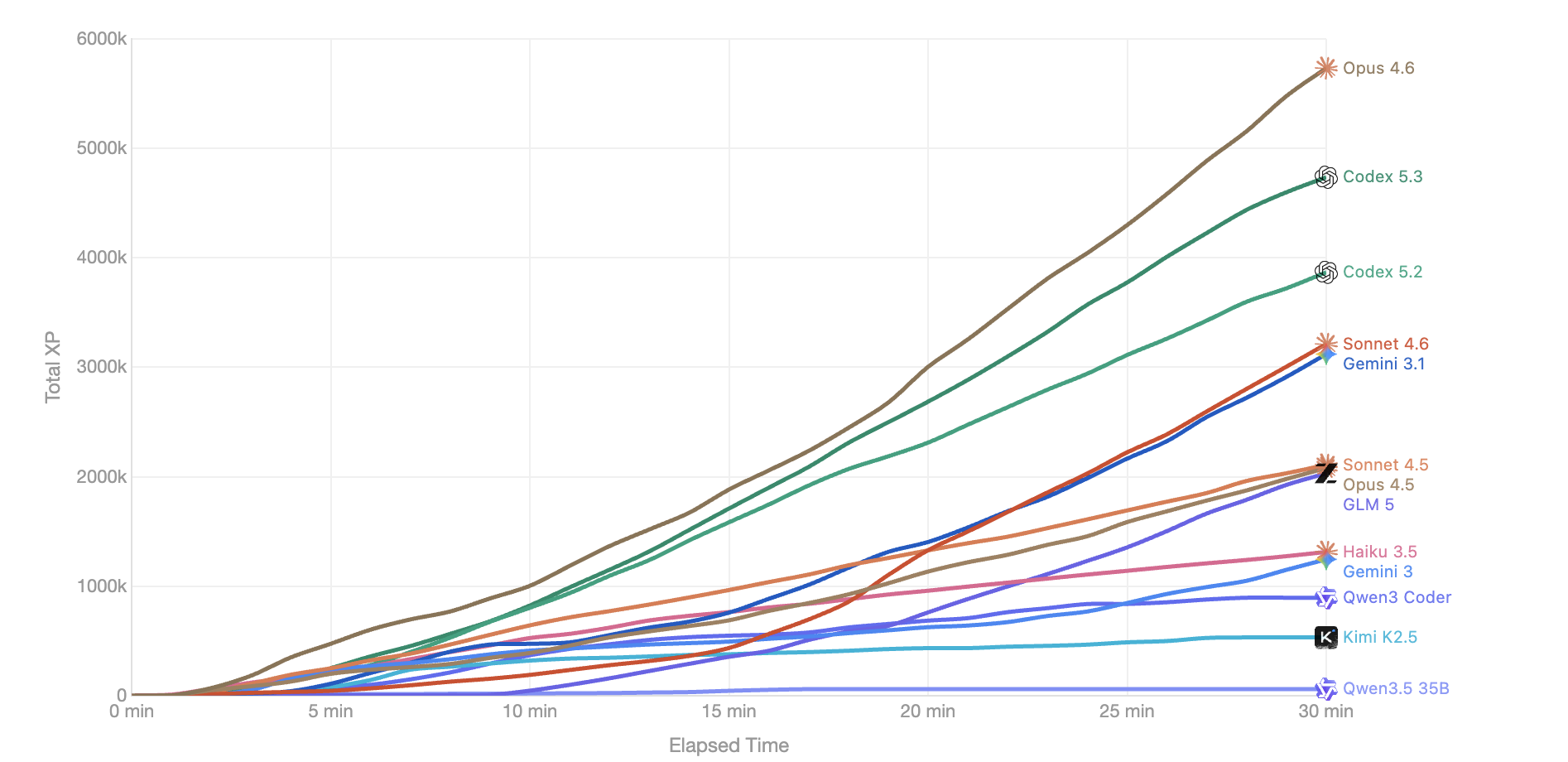
OPEN LINK ↗
// 1h agoBENCHMARK RESULT
OpenAI releases GeneBench-Pro biology benchmark
OpenAI has released GeneBench-Pro, a 129-problem benchmark designed to evaluate AI models on complex, noisy computational biology tasks. In initial testing, GPT-5.6 Sol achieved a 31.5% pass rate in Pro mode, highlighting progress in scientific reasoning while showing that expert autonomy remains in its early stages.
// ANALYSIS
Measuring expert-level workflow execution rather than static Q&A is the next frontier of LLM evaluation, and GeneBench-Pro shows how far we still have to go.
- –By using synthetic problems derived from known causal structures, the benchmark allows for deterministic grading of highly complex, open-ended tasks.
- –The stark contrast between GPT-5.6 Sol (31.5%) and prior models (under 5%) suggests that advanced reasoning architectures are starting to grasp multi-stage scientific workflows.
- –Forcing models to navigate noisy data and inferential forks exposes the limits of raw next-token prediction, emphasizing the need for robust planning and agentic execution.
// TAGS
openaibenchmarkcomputational-biologygenomicsgpt-5.6-solagentllmgenebench-pro
DISCOVERED
1h ago
2026-07-01
PUBLISHED
1h ago
2026-07-01
RELEVANCE
8/ 10
AUTHOR
gdb