OPEN LINK ↗
// 90d agoRESEARCH PAPER
TurboQuant fits 70B Llama on Mac
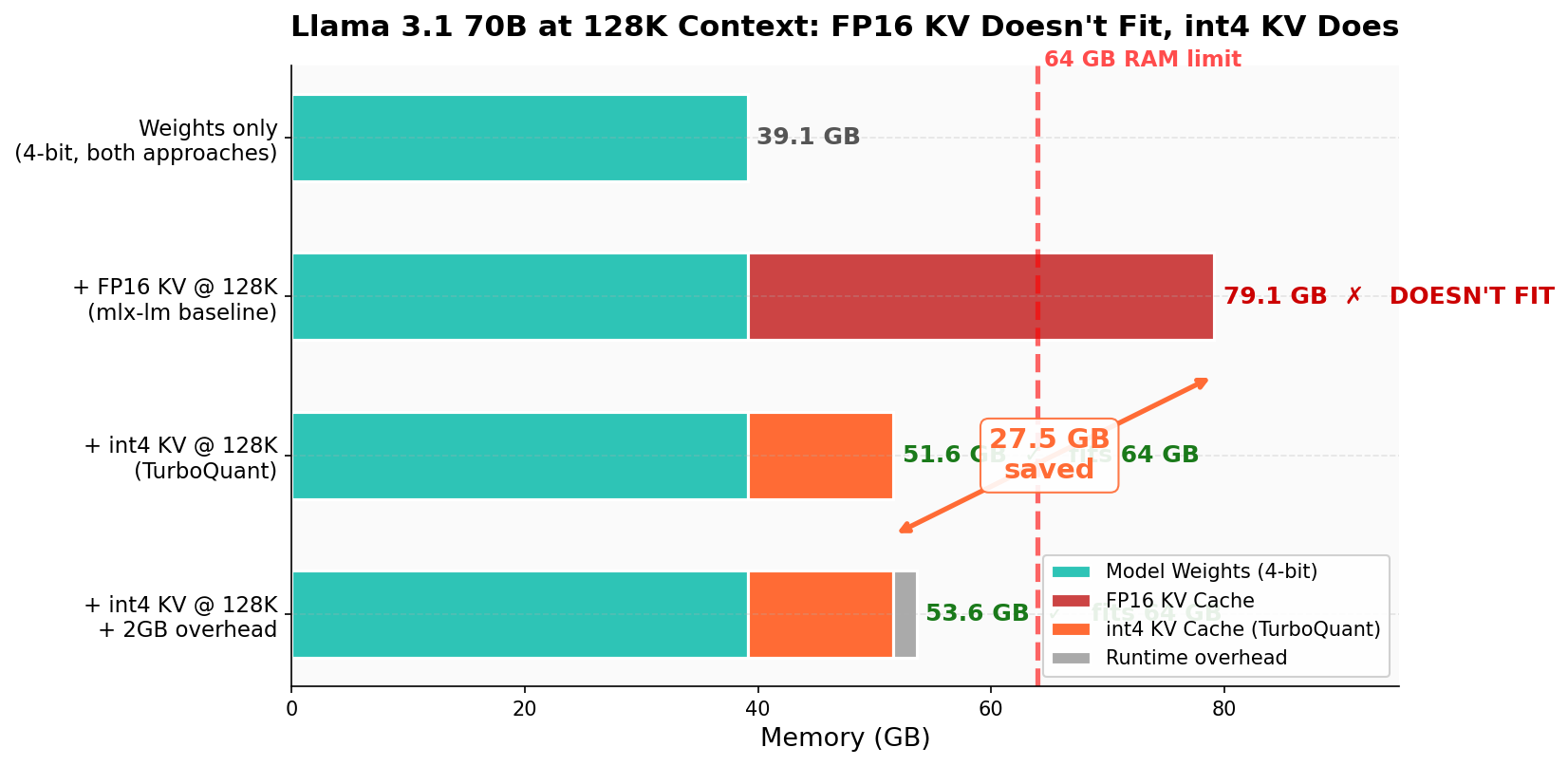
TurboQuant for Llama 3.1 70B is a new research/code release showing Llama 3.1 70B running at 128K context on a 64GB Apple Silicon Mac by using fused int4 KV-cache attention in Metal. The project reports 40GB to 12.5GB KV-cache reduction and a 48x attention-kernel speedup at 128K versus dequantize-then-attend.
// ANALYSIS
This is a sharp local-inference result because it attacks the real long-context bottleneck: KV memory, not just model weights.
- –The headline win is practical: a 4-bit 70B model plus 128K context reportedly drops from about 79GB to 53.6GB, making it fit on 64GB Macs
- –The fused Metal kernel matters because it computes attention directly over compressed int4 keys/values instead of rebuilding large temporary matrices
- –The 48x figure is attention-kernel speedup, not full end-to-end model speedup; the repo still reports around 6 tok/s decode
- –The paper’s negative results are useful too: QJL and PolarQuant ideas did not cleanly transfer to this 70B Apple Silicon setup, while simpler int4 won in practice
- –This is early, low-star research code, but it points toward consumer long-context inference becoming less absurdly hardware-gated
// TAGS
turboquant-for-llama-3.1-70bturboquantllama-3.1-70bllminferenceedge-aiopen-sourceresearch
DISCOVERED
90d ago
2026-04-22
PUBLISHED
90d ago
2026-04-21
RELEVANCE
9/ 10
AUTHOR
Zealousideal_Cat1508